
Research Paper Review: Vector Vs. Superscalar and VLIW Architectures for Embedded Multimedia Benchmarks
This report highlights VIRAM architecture’s efficiency for embedded multimedia applications, utilizing EEMBC benchmarks. With compact code, low power consumption, and reduced design complexity, VIRAM demonstrates superior performance, positioning it as the optimal choice over VLIW and Superscalar processors.
Paper Summary
The paper evaluates VIRAM components — the instruction set, vectorizing compiler, and processor microarchitecture. The paper shows that the compiler efficiently extracts data-level parallelism from C-described media tasks using vector instructions, resulting in significantly smaller or comparable code. VIRAM, with embedded DRAM and a cache-less vector processor issuing a single instruction per cycle, provides performance advantages for highly vectorizable benchmarks and partially vectorizable tasks with short vectors.
VIRAM, a load-store vector instruction set, extends the MIPS architecture as a coprocessor. The vector architecture state includes a 32-entry vector register file for integer or floating-point elements, a 16-entry flag register file with single-bit elements, and scalar registers for control values and memory addresses. The instruction set covers integer and floating-point arithmetic, logical functions, and operations like population count. Vector load and store instructions support unit stride, strided, and indexed access patterns.
For multimedia vectorization, VIRAM incorporates media-specific enhancements, allowing elements in vector registers to be 64, 32, or 16 bits wide. Narrow elements are stored in the location for one wide element, and the 64-bit datapath is partitioned for parallel execution of narrower element operations. Control registers, set once per loop group, replace specifying element and operation width in the instruction opcode. VIRAM supports saturated and fixed-point arithmetic, featuring a flexible multiply-add model without accumulators. Three vector instructions handle element permutations within registers, specifically for dot-products and FFTs. Conditional execution of element operations is supported for most vector instructions using flag registers as element masks.
VIRAM’s architecture includes features uncommon in traditional vector supercomputers, such as full support for paged virtual addressing using a separate TLB for vector memory accesses. It allows deferred saving and restoring of vector state during context switches and defines valid and dirty bits for vector registers to minimize vector state involvement in context switches.
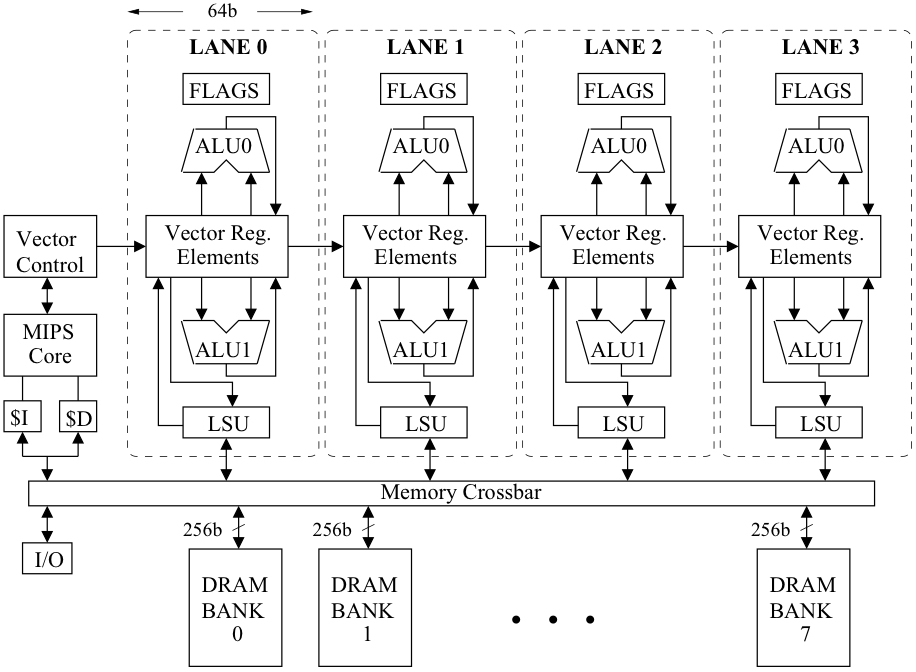
The VIRAM prototype processor features an on-chip main memory system based on embedded DRAM, offering high bandwidth crucial for a vector processor at moderate latency. The register and datapath resources in the vector coprocessor are vertically partitioned into four identical vector lanes, each with a 64-bit datapath from each functional unit. This parallel lane structure enhances performance, simplifies design, and promotes scalability. VIRAM achieves high performance by executing multiple element operations in parallel lanes for each vector instruction. VIRAM pipeline is a single-issue, in-order pipeline, with direct access to DRAM for vector load and store instructions that are deeply pipelined (15 stages) to mitigate latency. The intentionally low clock frequency (200 MHz), cache-less design, and modular implementation contribute to low power consumption and reduced design complexity, providing flexibility for scaling the vector processor’s performance, power consumption, and area.
The VIRAM compiler is derived from the PDGCS system for Cray supercomputers, and supports C, C++, and Fortran90. It has extensive capabilities for automatic vectorization, including outer-loop vectorization and handling of partially vectorizable language constructs.
To evaluate the efficiency of the VIRAM instruction set, microarchitecture, and compiler, we used the EEMBC benchmarks.
Results
The benchmarks mainly use 16-bit or 32-bit arithmetic operations supported by the VIRAM processor, with maximum vector lengths of 128 and 64 elements. Although not mandatory, long vectors offer significant advantages, enabling operations to leverage parallel vector lanes and achieve power efficiency through a single instruction fetch and decode, defining numerous independent operations.
VIRAM achieves excellent code density because its compiler avoids loop unrolling and software pipelining. When comparing VIRAM to its base RISC architecture, MIPS, the addition of vector instructions results in substantial reductions in code size.
While power dissipation figures are not directly comparable due to different CMOS technologies, VIRAM’s power includes main memory accesses, unlike others. Despite being unoptimized for low power, VIRAM’s microarchitecture, featuring parallel vector lanes and efficient control logic, leads to power savings. Superscalar, out-of-order processors like K6-III+ and MPC7455 exhibit higher power consumption due to their complex control logic and high clock rates. VLIW processors, with simpler designs and lower clock frequencies, demonstrate reduced power consumption despite high instruction issue rates. VIRAM’s power-efficient vector lanes and on-chip main memory contribute to its favorable power characteristics, delivering high bandwidth without the power overhead associated with off-chip interfaces or cache access for applications with limited temporal locality.
Comparing design complexity is challenging unless the same team implements all processors in the same technology with identical tools. Despite this, we assert that the VIRAM microarchitecture has notably lower complexity than superscalar processors. Both the vector coprocessor and main memory system are modular, featuring simple control logic without the need for caches or high clock frequency circuit design. This simplicity facilitated the implementation of the prototype chip by six graduate students with full-time coursework. In contrast, superscalar processors demand intricate control logic for out-of-order execution, often requiring hundreds of manyears for development. While VLIW processors are simpler than superscalar designs, their high instruction issue rate makes them more complex than single-issue vector processors, and VLIW architectures introduce significant complexity to compiler development.
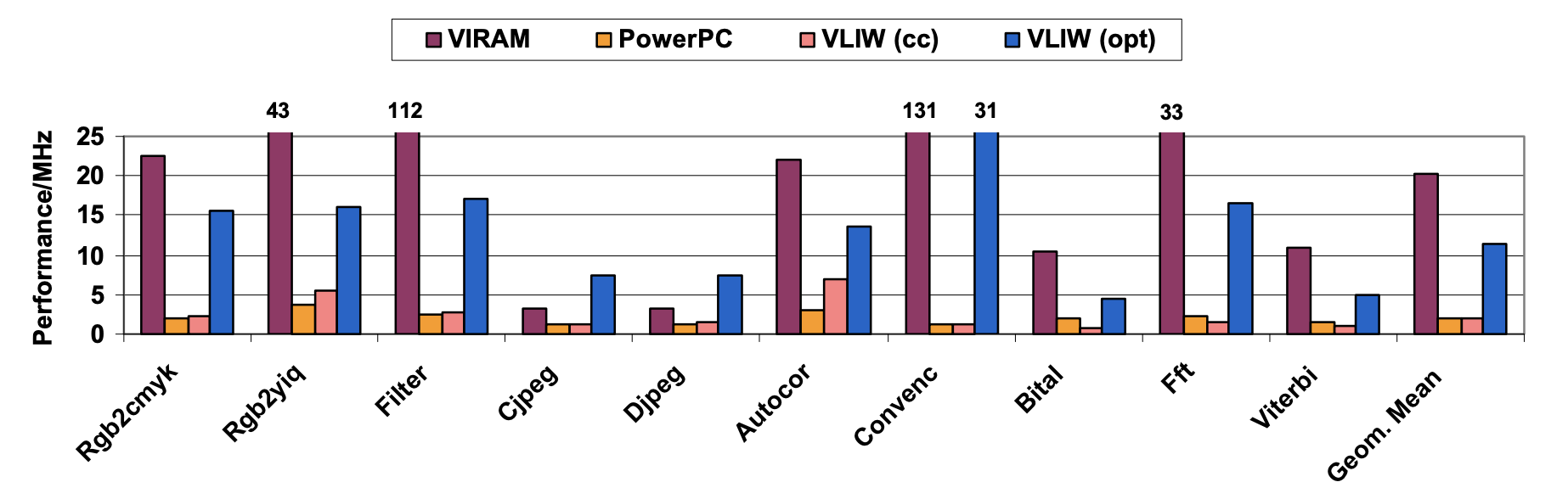
In EEMBC benchmarks, VIRAM, even with unoptimized code, surpasses x86, MIPS, and two VLIW processors (TM1300 and TMS320C605) by 2.5x to 6.1x for the geometric mean, but is 30% and 45% slower than the 1GHz MPC7455 PowerPC and optimized VLIW processors. With optimized code, VIRAM outpaces all processors by 1.6 to 18.5 times. Noteworthy is VIRAM’s single-issue design, absence of SRAM caches, and a clock frequency one-fifth that of the 4-way issue MPC7455. Considering contributions from microarchitecture and clock frequency, VIRAM and two VLIW designs could match or exceed superscalar processors’ clock speeds but opt for modest frequencies (166MHz to 300MHz) for power efficiency. In highly vectorizable benchmarks, VIRAM is up to 100 times faster than MPC7445 PowerPC. For benchmarks with strided and indexed memory accesses, VIRAM outperforms MPC7455 by a factor of 10. In partially vectorizable benchmarks, VIRAM maintains a 3x to 5x performance advantage over MPC7455, showcasing the efficiency of simple vector hardware with data-level parallelism.
Original benchmark code shows similar performance between the two VLIW processors and superscalar designs. Optimizations and manual insertion of SIMD and DSP instructions bring VLIW designs within 50% of VIRAM with optimized code. In consumer benchmarks, restructuring code for Cjpeg and Djpeg significantly improves TM1300 VLIW performance. For telecommunication benchmarks, TMS320C605 VLIW design benefits from DSP features. Achieving comparable performance for an architecture combining VLIW and DSP characteristics is challenging for compilers.
VIRAM’s microarchitecture allows higher performance and lower power consumption than superscalar and VLIW processors in EEMBC benchmarks. Normalizing performance by an acceptable design complexity metric would likely yield similar results. The EEMBC scores for VIRAM in consumer and telecommunications benchmarks are 81.2 and 12.4, respectively, with unscheduled code. With optimized code, scores are 201.4 and 61.7, respectively. Additionally, optimized VIRAM vector code outperforms scalar code on its simple MIPS core by over 20 times for all benchmarks.
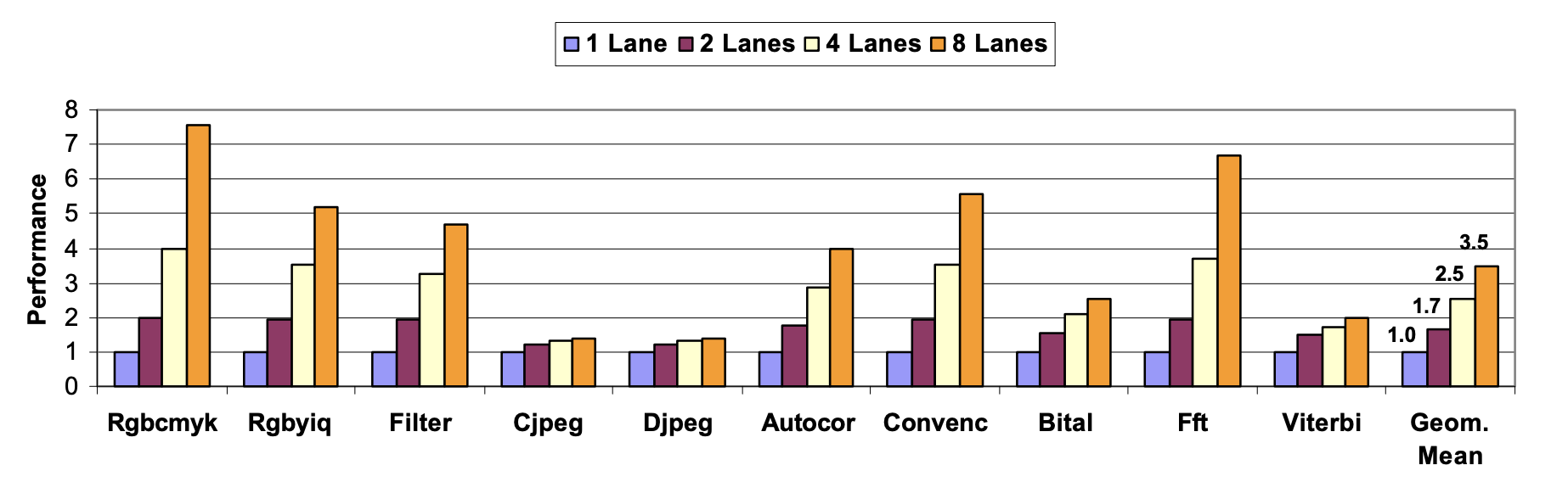
Organizing vector hardware in lanes allows easy scaling of performance, power consumption, and area by adjusting the number of lanes. Additional lanes benefit benchmarks with long vectors, such as Rgb2cmyk, Convenc, and Fft, while those with short vectors like Cjpeg, Djpeg, and Viterbi show minimal improvement. Overall, the geometric mean indicates good scaling, with two, four, and eight lanes providing approximately 1.7x, 2.5x, and 3.5x performance improvement, respectively, a challenge for other architectures like superscalar or VLIW processors.
Critical Review
Pros
Vector architectures offer an ideal solution for embedded multimedia processing, combining high performance, low power consumption, and reduced complexity. The addition of a vector unit to a media processor enhances overall efficiency. VIRAM demonstrates remarkable code density, comparable to x86 and significantly outperforming optimized VLIW architectures by 5-10 times. In terms of performance, even without manual optimization, VIRAM achieves double the performance of a 4-way out-of-order superscalar processor, surpassing it by 50% compared to a manually-optimized 5 to 8-way VLIW processor, which includes hand-inserted SIMD and DSP support.
Cons
The VIRAM processor exhibits certain drawbacks that the paper does not extensively discuss. Firstly, its performance gains heavily rely on compiler vectorization, potentially limiting its adaptability to new or customized applications and programming scenarios. The paper briefly addresses challenges with the vector memory system, but specific details about potential drawbacks or optimizations in this regard remain undisclosed. While excelling in multimedia processing, the VIRAM architecture may prove less versatile for tasks beyond the scope of multimedia applications, given its specialized design. Additionally, the intentional operation of the VIRAM processor at a low clock frequency, aimed at enhancing power efficiency, may introduce a performance trade-off, particularly for applications that benefit from higher clock speeds.
Takeaways
Efficient media processing on superscalar and VLIW processors often relies on SIMD extensions like SSE and Altivec, but these have limitations. They define operations on short vectors, and the overhead of emulating vector memory accesses can offset SIMD benefits. Recent vector architecture research has mainly adapted techniques from superscalar designs to accelerate scientific applications. While some studies on vector processors exist, previous challenges include vector memory system performance and automatic vectorization. This paper addresses these issues with the embedded DRAM in VIRAM’s memory system and a Cray-based vectorizing compiler. The Imagine stream processor offers an alternative multimedia processing architecture, utilizing clusters and microcoded control for flexible data-level parallelism. However, its programming model is complex, requiring a specialized C dialect, while VIRAM uses a more straightforward approach based on standard C or C++ with automatic vectorization.
References
- C. Kozyrakis and D. Patterson, “Vector vs. superscalar and vliw architectures for embedded multimedia benchmarks,” in 35th Annual IEEE/ACM International Symposium on Microarchitecture, 2002. (MICRO-35). Pro- ceedings., 2002, pp. 283–293.