
Research Paper Review: PRIME
In this paper, the researchers propose PRIME, a novel PIM architecture designed to accelerate NN applications within ReRAM-based main memory. PRIME allows for a portion of ReRAM crossbar arrays to be configured either as NN accelerators or as conventional memory, thereby expanding the available memory space. The researchers offer microarchitecture and circuit designs to facilitate these versatile functions with minimal area overhead. Additionally, they devise a software/hardware interface to enable software developers to deploy various NN models on PRIME. By leveraging both the advantages of PIM architecture and the efficiency of ReRAM for NN computation, PRIME distinguishes itself from previous NN acceleration approaches, yielding notable performance enhancements and energy savings. Experimental results demonstrate that PRIME improves performance by approximately 2360\(\times\) and reduces energy consumption by around 895\(\times\) compared to a state-of-the-art neural processing unit design, across various machine learning benchmarks.
Paper Summary
Traditional computer systems rely on separate components for processing (CPUs and GPUs) and data storage (memory, flash, and disks). With the exponential growth in data volume over the past decade, the movement of data between processing units (PUs) and memory has become a significant bottleneck in performance and energy efficiency for various computer systems, from cloud servers to end-user devices. For instance, transferring data between CPUs and off-chip memory consumes significantly more energy than performing a floating point operation.
Recent advancements in processing-in-memory (PIM) techniques offer promising solutions to these challenges by integrating computation logic with memory using 3D memory technologies. Recent studies have shown that emerging non-volatile memories like metal-oxide resistive random access memory (ReRAM), spin-transfer torque magnetic RAM (STT-RAM), and phase change memory (PCM) can perform logic and arithmetic operations in addition to data storage. This capability allows memory to function both as a storage unit and a computational unit, potentially revolutionizing the traditional relationship between computation and memory. ReRAM, in particular, demonstrates efficient matrix-vector multiplication in a crossbar structure and has been extensively studied for representing synapses in neural computation.
Neural networks (NN) and deep learning (DL) are increasingly recognized for their potential to offer optimal solutions in various applications like image/speech recognition and natural language processing. However, as NN sizes grow significantly, state-of-the-art algorithms such as multi-layer perceptron (MLP) and convolutional neural network (CNN) demand extensive memory capacity. Achieving high-performance acceleration for NN requires ample memory bandwidth since PUs heavily rely on fetching synaptic weights.
Recent advancements have seen special-purpose chip designs incorporating large on-chip memory to store synaptic weights, such as DaDianNao utilizing eDRAM and TrueNorth employing SRAM crossbar memory for synapses in each core. While these solutions effectively reduce the need to transfer synaptic weights between PUs and off-chip memory, challenges persist due to data movement, including input and output data, besides synaptic weights, hindering performance improvement and energy savings.
PIM emerges as a promising solution to address this issue by embedding computation logic into the memory chip. This approach allows NN computation to leverage large memory capacity while sustaining high memory bandwidth through in-memory data communication.
In this paper, the team proposes PRIME, a novel PIM architecture designed for efficient NN computation using ReRAM crossbar arrays within ReRAM-based main memory. ReRAM has emerged as a potential candidate for next-generation main memory due to its attributes such as large capacity, fast read speed, and computational capabilities. In the proposed design, a portion of memory arrays is designated to serve as NN accelerators alongside normal memory. The circuit, architecture, and software interface designs enable dynamic reconfiguration of these ReRAM arrays between memory and accelerators, accommodating various NN configurations. The current PRIME design supports large-scale MLPs and CNNs, achieving state-of-the-art performance across various NN applications, including top classification accuracy for image recognition tasks. Distinguished from prior work on NN acceleration, PRIME leverages both ReRAM efficiency for NN computation and the effectiveness of the PIM architecture in reducing data movement overhead, resulting in significant performance gains and energy savings. As it does not require a dedicated processor, PRIME incurs minimal area overhead and is cost-effective to manufacture, remaining as a memory design without the need for complex logic integration or 3D stacking.
This paper makes significant contributions in several key areas. Firstly, it introduces a ReRAM main memory architecture featuring memory arrays (full function subarrays) that can dynamically switch between serving as NN accelerators or normal memory. This novel PIM approach capitalizes on in-memory data movement and the computational efficiency of ReRAM. Secondly, the paper presents the design of circuits and microarchitecture to facilitate NN computation within memory while minimizing area overhead through careful design considerations, such as reusing peripheral circuits for both memory and computation tasks. Thirdly, practical solutions are proposed to address precision challenges associated with utilizing ReRAM crossbar arrays for NN computation, including an input and synapse composing scheme. Lastly, the development of a software/hardware interface enables software developers to configure full function subarrays for various NN implementations, optimizing NN mapping during compile time and exploiting ReRAM memory’s bank-level parallelism for enhanced acceleration.
Results
Experiment Setup
Benchmark
The evaluation employs MlBench benchmarks, encompassing six NN designs tailored for machine learning tasks. These designs consist of two convolutional neural networks (CNN-1 and CNN-2) and three multilayer perceptrons (MLP-S/M/L), varying in scale from small to large networks. Their performance is assessed using the MNIST database of handwritten digits. Additionally, the evaluation includes VGG-D, a well-known NN utilized in ImageNet ILSVRC. VGG-D is characterized by its extensive architecture, comprising 16 weight layers and \(1.4\times10^8\) synapses, with an operational requirement of \(\sim 1.6\times10^{10}\) operations.
PRIME Configurations
Each bank comprises 2 Full Function (FF) subarrays and 1 Buffer subarray, totaling 64 subarrays. In the FF subarrays, each matrix consists of 256\(\times\)256 ReRAM cells and eight 6-bit reconfigurable Synaptic Arrays (SAs). ReRAM cells assume 4-bit Multi-Level Cell (MLC) for computation and Single-Level Cell (SLC) for memory. For computation, input voltage features 8 levels (3-bit), while for memory, it’s limited to 2 levels (1-bit). Our input and synapse composing scheme enables 6-bit dynamic fixed point for inputs and outputs, with 8-bit weights for computation.
Methodology
The study compares PRIME with several counterparts. The baseline comprises a CPU-only solution along with essential memory timing parameters for simulation. Additionally, two different NPU solutions are evaluated: one utilizing a complex parallel NPU as a co-processor (pNPU-co), and the other employing the NPU as a PIM-processor through 3D stacking (pNPU-pim). These NPU designs are modeled using Synopsys Design Compiler and PrimeTime with a 65\(nm\) TSMC CMOS library. ReRAM main memory and the PRIME system are modeled using modified NVSim, CACTI-3DD, and CACTI-IO. Pt/TiO2-x/Pt devices with specific electrical characteristics are adopted. The FF subarray is simulated using heavily modified NVSim to incorporate peripheral circuit modifications such as write drivers, sigmoid circuits, and sense amplifiers. A trace-based in-house simulator is developed to evaluate various systems, including CPU-only, PRIME, NPU co-processor, and NPU PIM-processor.
Performance Results
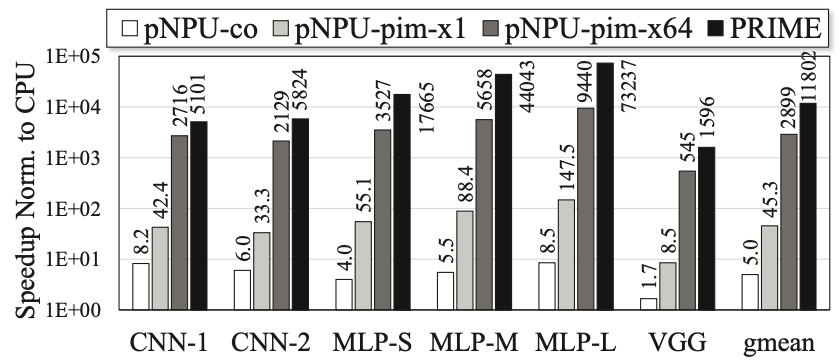
Figure 1 presents the performance results for MlBench benchmarks. These benchmarks involve large NNs that demand high memory bandwidth, making them suitable candidates for PIM. To showcase the advantages of PIM, two pNPU-pim solutions are evaluated: pNPU-pim-x1, featuring a single parallel NPU stacked on top of memory, and pNPU-pim-x64, incorporating 64 NPUs for comparison with PRIME, which exploits bank-level parallelism (64 banks). Comparing the speedups of pNPU-co and pNPU-pim-x1 reveals that the PIM solution achieves an average 9.1\(\times\) speedup over the co-processor solution. Among all solutions, PRIME achieves the highest speedup over the CPU-only solution, approximately 4.1\(\times\) that of pNPU-pim-x64. Notably, PRIME exhibits a smaller speedup in VGG-D compared to other benchmarks due to the extensive mapping required across 8 chips, where data communication between banks/chips is costly. PRIME’s performance advantage over the 3D-stacking PIM solution (pNPU-pim-x64) for NN applications stems from the efficiency of using ReRAM for NN computation, as synaptic weights are pre-programmed in ReRAM cells and do not necessitate data fetches from main memory during computation. Latency and energy consumption of configuring ReRAM for computation are not included in our performance and energy evaluations of PRIME, as it is assumed that once configured, NNs will be executed numerous times to process different input data.
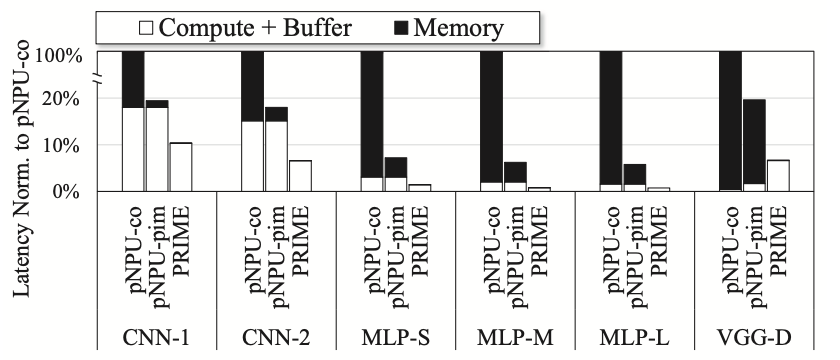
Figure 2 illustrates the breakdown of execution time normalized to pNPU-co. To provide a clear breakdown, the researchers assess the results of pNPU-pim with a single NPU, and PRIME without utilizing bank parallelism for computation. The execution time is divided into two components: computation and memory access. The computation segment also encompasses the time spent on buffers of NPUs or the Buffer subarrays of PRIME in managing data movement. It is observed that pNPU-pim significantly reduces memory access time, with PRIME further reducing it to zero. A zero memory access time does not indicate the absence of memory access, but rather suggests that the memory access time can be concealed by the Buffer subarrays.
Energy Results
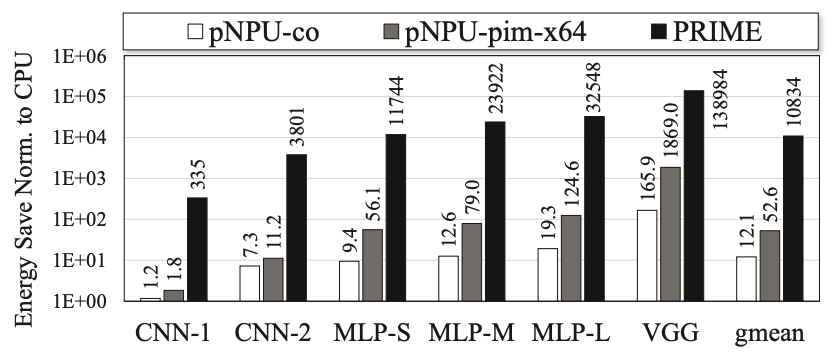
Figure 3 presents the energy-saving outcomes for MlBench. Notably, the results for pNPU-pim-x1 are omitted as they align with those of pNPU-pim-x64. PRIME demonstrates superior energy efficiency compared to other solutions depicted in the figure. pNPU-pim-x64 exhibits several times greater energy efficiency than pNPU-co, attributable to the PIM architecture’s reduction of memory accesses and energy savings. The energy advantage of PRIME over the 3D-stacking PIM solution (pNPU-pim-x64) for NN applications stems from the energy efficiency of utilizing ReRAM for NN computation.
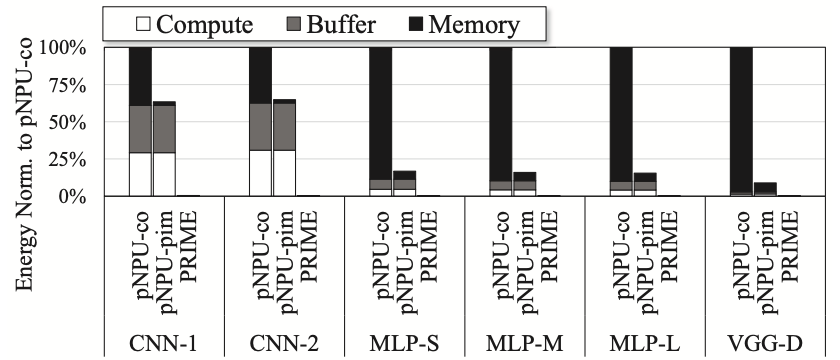
Figure 4 illustrates the breakdown of energy consumption normalized to pNPU-co. Total energy consumption is categorized into three parts: computation energy, buffer energy, and memory energy. Notably, pNPU-pim-x64 consumes nearly the same energy in computation and buffer as pNUP-co but achieves a 93.9% average reduction in memory energy by decreasing memory accesses and minimizing memory bus and I/O energy. PRIME significantly reduces energy consumption across all three categories. ReRAM-based analog computing proves highly energy-efficient for computation. Additionally, the ability of each ReRAM matrix to store 256\(\times\)256 synaptic weights eliminates cache and memory accesses for fetching synaptic weights. Moreover, as each ReRAM matrix can execute as large as a 256\(\times\)256 neural network at once, PRIME also reduces buffer and memory accesses for temporary data. CNN benchmarks exhibit higher energy consumption in buffer and lower energy consumption in memory compared to MLP benchmarks. This discrepancy arises from the smaller number of input data, synaptic weights, and output data typically seen in convolution and pooling layers of CNNs, making buffers effective in reducing memory accesses.
Area Overhead
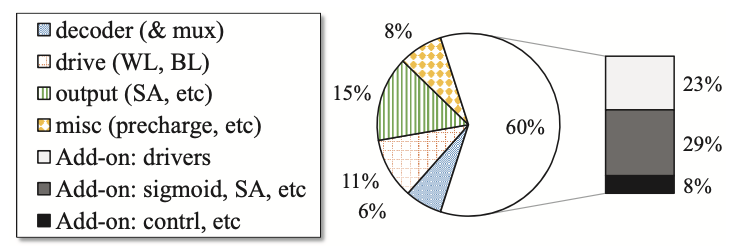
PRIME utilizes two FF subarrays and one Buffer subarray per bank, totaling 64 subarrays, resulting in a mere 5.76% area overhead. The selection of the number of FF subarrays involves a balance between peak GOPS (Giga Operations Per Second) and area overhead. Experimental findings on Mlbench (excluding VGG-D) indicate that the utility of FF subarrays averages at 39.8% before replication and 75.9% after replication. For VGG-D, the utility of FF subarrays stands at 53.9% before replication and 73.6% after replication. Figure 5 illustrates the breakdown of area overhead in a mat of an FF subarray. Notably, there is a 60% increase in area to support computation: the added driver accounts for 23%, subtraction and sigmoid circuits contribute 29%, while control, multiplexer, and other components amount to 8%.
Critical Review
Pros
- PRIME proposes a novel approach by integrating PIM architecture within ReRAM-based main memory, addressing performance and energy efficiency concerns for NN applications.
- The experimental results demonstrate significant speedup and energy savings across various NN applications, showcasing the effectiveness of PRIME in enhancing performance.
- PRIME achieves minimal area overhead through circuit reuse, ensuring that the integration of PIM architecture does not significantly impact the original ReRAM chips.
- PRIME offers flexibility by allowing a portion of ReRAM memory arrays to serve either as accelerators for NN applications or as memory, providing a larger working memory space.
Cons
- While PRIME offers significant benefits, its implementation has introduced complexity, especially in terms of system integration and software/hardware interface development.
Takeaways
This paper introduces PRIME, a novel PIM architecture embedded within ReRAM-based main memory, aimed at significantly enhancing performance and energy efficiency for NN applications. PRIME leverages both the advantages of PIM architecture and the efficiency of ReRAM-based NN computation. Within PRIME, a portion of ReRAM memory arrays is equipped with NN computation capability, capable of either accelerating NN applications or functioning as memory to expand working memory space. Our designs span from circuit-level to system-level, with PRIME achieving minimal area overhead through circuit reuse. Experimental results demonstrate PRIME’s ability to achieve high speedup and substantial energy savings across various NN applications, including MLP and CNN.
References
- P. Chi, S. Li, C. Xu, T. Zhang, J. Zhao, Y. Liu, Y. Wang, and Y. Xie, “Prime: A novel processing-in-memory architecture for neural network computation in reram-based main memory,” in 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016, pp. 27–39.