
Research Paper Review: Understanding Sources of Inefficiency in General-Purpose Chip
This paper compares general-purpose processors, including CMPs, to ASICs in terms of cost-effectiveness, performance, and energy efficiency. It focuses on a 720p HD H.264 encoder running on a CMP system to identify performance and energy overheads. The paper proposes transforming the CPU into a specialized system for H.264 encoding to eliminate these overheads. Various optimizations are explored, including SIMD units and customized storage and functional units, to improve performance and energy efficiency.
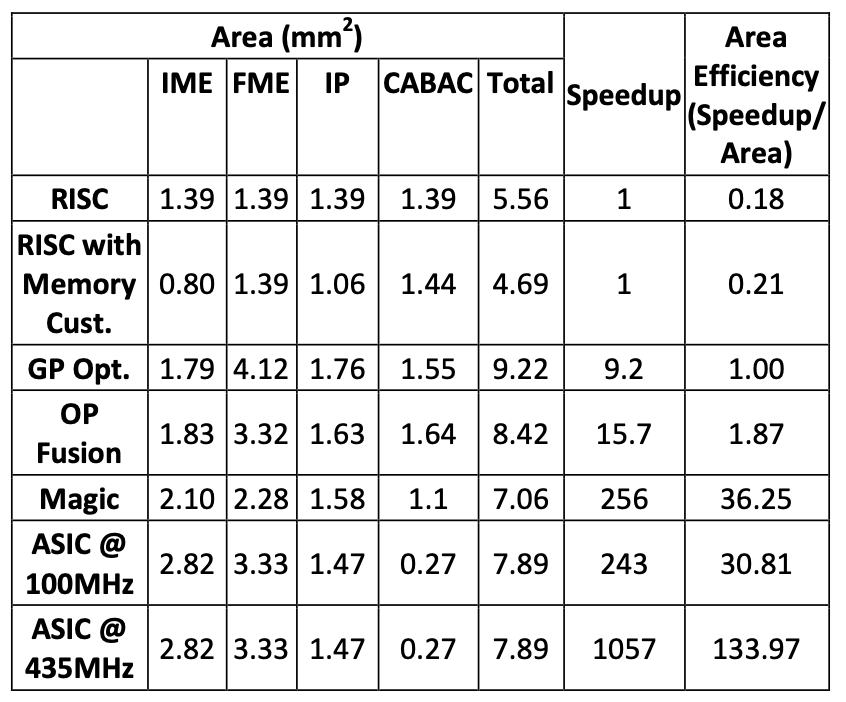
The ASIC is found to be 500\(\times\) more energy efficient than the original CMP. Broad optimizations enhance performance by 10\(\times\) and energy efficiency by 7\(\times\), but most of the energy is still considered overhead due to the low energy costs of core operations. Achieving ASIC-like performance and efficiency necessitates algorithm-specific optimizations. For each sub-algorithm of H.264, large specialized functional units are created, resulting in a 25\(\times\) improvement in performance and energy efficiency. The final customized CMP achieves performance comparable to an ASIC solution within 3\(\times\) the energy usage and comparable area.
Paper Summary
In contemporary computing, systems face power limitations. As technology scaling no longer yields the energy savings it once did, designers seek alternative methods for performance enhancement and manageable energy costs. One promising avenue is understanding and integrating the efficiencies of ASICs, which can surpass general-purpose processors by three orders of magnitude in both performance and energy efficiency. To achieve ASIC-like efficiencies with the development cost of microprocessors, designers are exploring two areas: creating CPU designs with lower energy per instruction and devising new methodologies to reduce the cost of custom hardware creation. These approaches require understanding the quantitative aspects of energy overheads in general-purpose processors to explore eliminating them and evaluate the feasibility of creating efficient general-purpose machines. This paper quantifies general-purpose overheads, exploring customizations to achieve ASIC-like efficiency, including exploiting instruction- and data-level parallelism, customizing instructions, and creating application-specific data storage with fused functional units. The evaluation involves transforming a general-purpose, Tensilica-based, extensible CMP system into a highly efficient 720p HD H.264 encoder, chosen for its computational variety and benchmarking capabilities. Despite significant customizations improving energy efficiency by 10\(\times\), the resulting solution remains 50\(\times\) less energy efficient than an ASIC. An examination of the energy breakdown reveals the need for instructions aggregating enough computation to offset the energy overheads of flexible instruction and data fetch. Creating such instructions improves energy efficiency by another 18\(\times\), bringing the solution within 3\(\times\) of a full ASIC design. Identifying appropriate customizations for specific applications requires significant effort, emphasizing the necessity of application-specialized hardware for truly efficient designs. The paper underscores the importance of frameworks enabling application experts to create customized solutions easily and at low cost, demonstrating promising efficiency using processor instruction extensions. Finally, the paper reviews prior work, presents experimental methodology, performance gains, and explores implications for efficient computing and application-driven design.
To comprehend the customization process of a generic CMP for efficient H.264 implementation, understanding the fundamental components of the H.264 algorithm is crucial. The algorithm comprises five major functions, namely Integer Motion Estimation (IME), Fractional Motion Estimation (FME), Intra Prediction (IP), Transform and Quantization (DCT/Quant), and Context Adaptive Binary Arithmetic Coding (CABAC). Implementing the H.264 baseline profile at level 3.1, CABAC replaces CAVLC due to its complexity, representing advanced coding steps. IME identifies the closest match for an image-block from a reference image, consuming 56% of the total encoder execution time and 52% of total energy. FME refines the match at quarter-pixel resolution, accounting for 36% of execution time and 40% of energy. IP predicts the current image-block using neighboring blocks, while DCT/Quant transforms and quantizes the difference between the current and predicted blocks. Finally, CABAC encodes coefficients and bit-stream elements sequentially, constituting 1.6% of execution time and 1.7% of energy. Despite its low percentage, CABAC can become a bottleneck in parallel systems, especially when aiming for significant speedups on a four-processor system.
The H.264 encoding algorithm, recognized for its computational intensity, is predominantly implemented using ASICs due to their efficiency. Previous studies have showcased effective hardware architectures for various sub-algorithms in H.264, such as T.-C. Chen et al., who achieved real-time HD H.264 encoding with low power and area costs. While subsequent implementations have optimized algorithms, sacrificing some signal-to-noise ratio (SNR) to reduce energy and area, this paper concentrates on fundamental algorithms akin to those in prior research to comprehend the mechanisms behind high-efficiency custom hardware, expected to be consistent across algorithmic variants.
Extensive efforts have been made in software optimizations for H.264, particularly in motion estimation. Techniques like sparse search and algorithmic modifications have notably accelerated software performance with minimal SNR loss. Combining these modifications with multiple cores and SSE extensions has resulted in highly optimized H.264 encoders on Intel processors. However, despite these optimizations, software implementations still fall short compared to dedicated ASICs. A comparison between a software encoder and an ASIC implementation reveals significant disparities in energy consumption and area efficiency. The ASIC consumes over 500\(\times\) less energy and utilizes silicon area more effectively, with negligible drops in compression efficiency due to fewer algorithmic simplifications.
The experiments utilize a CMP platform based on Tensilica’s extensible RISC cores, setting the baseline for bridging the gap between general-purpose computing and ASIC efficiencies. Three classes of customizations are implemented, each more application-specific than the previous. Processor datapaths are individually customized using Tensilica’s TIE language, and memory system parameters are optimized. A multiprocessor simulation framework employing Tensilica’s XTMP is created to simulate and evaluate different design options. The H.264 encoder reference code JM 8.6 is used for experiments, with algorithmic changes made in IME to exploit task-level parallelism and reduce inter-processor communication bandwidth requirements. Mapping the H.264 partition to a four-processor CMP system reveals significant gaps in area and energy efficiency compared to the reference ASIC. Performance and energy efficiency analysis show a substantial disparity between the CMP and ASIC implementations, especially in major tasks like IME and FME. Further improvements are necessary, including customizing functional units and minimizing processor overheads, to approach ASIC efficiency.
The paper defines three classes of processor customization. In the first stage, the focus is on relatively general-purpose datapath extensions like SIMD and VLIW units, commonly found in modern processor designs. These extensions are expected to remain integral to future efficient processors. Moving to the second stage involves adding a limited degree of algorithm-specific customization, particularly through operation fusion, which creates new instructions by combining sequences of existing ones. These new instructions adhere to operand requirements matching existing instructions and must fit within existing instruction formats and datapath, akin to Intel’s SSE instructions. Such customizations, especially for key functions, are likely to persist in future processors. Finally, in the third stage, there’s unrestricted tailoring of the datapath to meet algorithmic needs, allowing the introduction of arbitrary new compute operations and potentially replacing register files with custom storage structures.
Results
The three customization strategies are implemented and assessed, providing a detailed analysis of their effectiveness. Strategies for algorithm-specific instructions are delineated for each major computation phase. Collectively, these findings demonstrate an improvement of 170\(\times\) over the baseline.
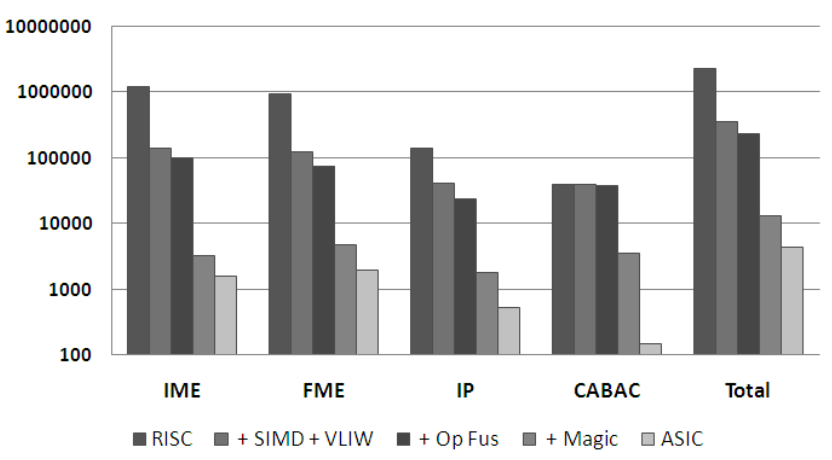
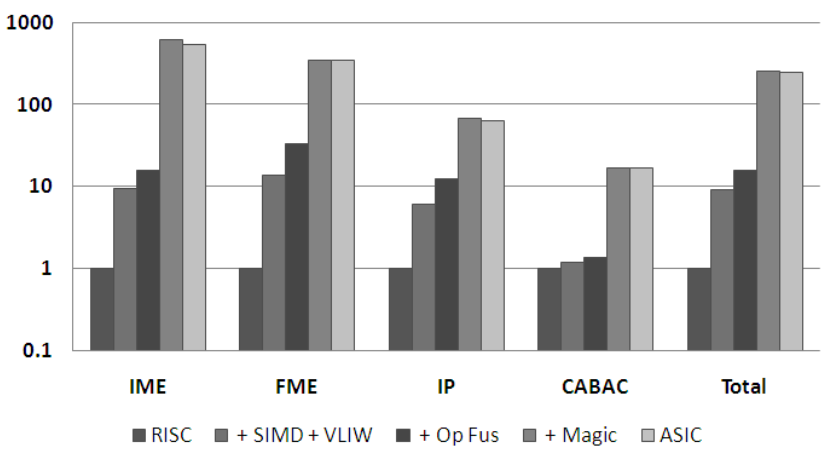
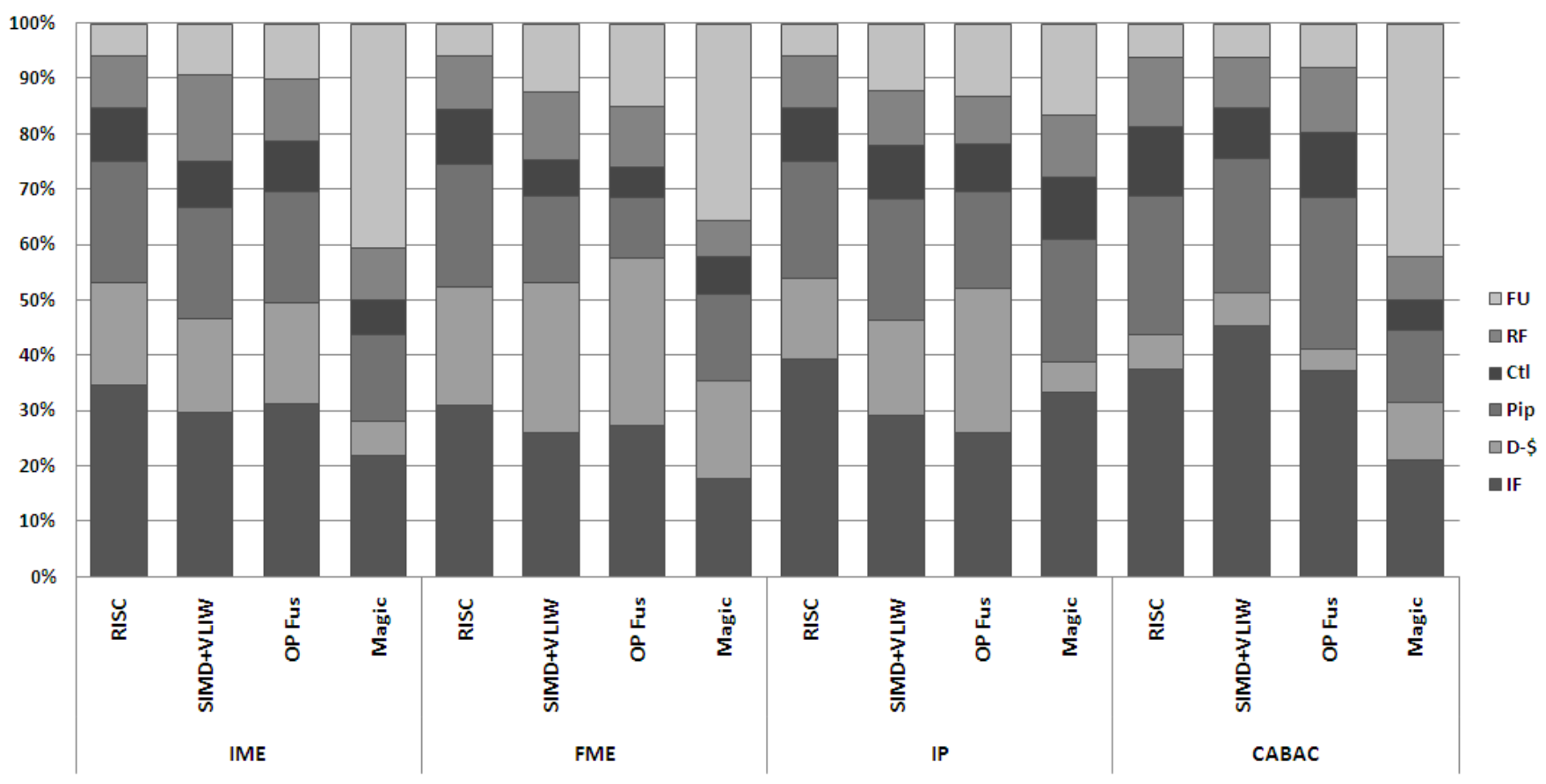
Processors are customized using Tensilica’s FLIX feature to include 2- and 3-slot VLIW instructions, alongside the addition of SIMD execution units through TIE, featuring custom vector register files. The utilization of SIMD units results in a notable reduction in processor energy, with significant speedups observed in data-parallel algorithms such as IME and FME, achieving 10\(\times\) and 14\(\times\) speedups respectively. The SIMD units employ custom-width functional units, maintaining a consistent percentage of total energy usage despite executing multiple operations concurrently. Furthermore, VLIW instructions enhance the performance of H.264 sub-algorithms, with 2-slot VLIW demonstrating higher energy efficiency compared to 3 slots, achieving up to 1.5x more performance. However, VLIW instructions increase code size for CABAC, offsetting energy gains. Despite improvements from SIMD and VLIW, energy consumption by instruction fetch remains high, and CABAC’s power dissipation remains a significant factor in overall power usage.
Combining fused operations with SIMD/VLIW yields an overall performance improvement of 15\(\times\) for the H.264 encoder and nearly 10\(\times\) energy efficiency gain, yet still consumes over 50\(\times\) more energy than an ASIC. The core issue lies in the simplicity and low energy consumption of basic operations in H.264. While tailoring the functional unit width in the SIMD machine reduces required energy, executing numerous narrow width operations per instruction results in a machine expending 90% of its energy on overhead functions, with only 10% allocated to functional units.
The paper proposes closing the remaining gap by introducing instructions capable of executing hundreds of operations simultaneously. This heightened level of parallelism necessitates instructions intricately linked to custom data storage elements, featuring algorithm-specific communication links closely aligned with optimized algorithmic methods. These storage elements can directly interface with custom-designed functional units, facilitating hardware-based communication for the function. Once established, the system can utilize “magic” instructions, significantly reducing processor overheads by eliminating most communication overheads associated with processors. These “magic” instructions, noted for their substantial impact on energy and performance, are challenging to derive directly from code and typically require a deep understanding of underlying algorithms and hardware limitations. The focus of the paper remains on FME, IME, and CABAC, given their similarity to techniques used in the IP stage.
Critical Review
Pros
- Clear Exploration of Optimization Strategies: The paper provides a detailed exploration of various optimization strategies, including SIMD execution units, VLIW instructions, and customizations of datapaths, to improve performance and energy efficiency.
- Comprehensive Analysis: It offers a comprehensive analysis of the effectiveness of each optimization strategy, including their impact on energy consumption, performance gains, and area efficiency.
Cons
- Lack of Benchmarking: While the paper discusses performance gains and energy efficiency improvements, it could benefit from direct comparisons with existing benchmarks or state-of-the-art approaches to provide more context and validation of the results.
- Complexity of Customizations: The customization strategies discussed in the paper, such as operation fusion and algorithm-specific optimizations, may require significant expertise and effort to implement effectively, potentially limiting their practical adoption by developers.
Takeaways
The research aims to achieve ASIC-like energy efficiencies—100 to 1000 times more energy-efficient than general-purpose CPUs—on upcoming processors. However, the data suggests that this goal will be challenging to accomplish. The main obstacle lies in the fact that many applications involve simple, low-energy operations, causing any overhead in a processor to become significant.
Despite the challenge, the study demonstrates that achieving ASIC-level energy consumption in a customized processor is possible by integrating tailored hardware within a processor framework, enabling the execution of hundreds of simple operations per instruction. Opting to extend a processor rather than constructing an ASIC appears to be a promising approach, offering several software development benefits with minimal energy costs.
Moving forward, the primary challenge is to develop a design system that allows application designers to create such customizations more effortlessly.
References
- R.Hameed, W.Qadeer, M.Wachs, O.Azizi, A.Solomatnikov, B.C.Lee, S. Richardson, C. Kozyrakis, and M. Horowitz, “Understanding sources of inefficiency in general-purpose chips,” in Proceedings of the 37th Annual International Symposium on Computer Architecture, ser. ISCA ’10. New York, NY, USA: Association for Computing Machinery, 2010, p. 37–47. [Online]. Available: https://doi.org/10.1145/1815961.1815968