
Research Paper Review: Gemmini
The paper introduces Gemmini, an open-source tool for creating DNN accelerators. Gemmini generates a diverse range of efficient ASIC accelerators using a flexible architectural template. It also provides adaptable programming stacks and complete SoCs with shared resources to capture system-level impacts. Gemmini-generated accelerators have been fabricated and demonstrate significant speed improvements, up to three orders of magnitude faster than high-performance CPUs, across various DNN benchmarks.
Paper Summary
In recent years, deep neural networks (DNNs) have become increasingly popular across various fields like computer vision, machine translation, and robotic manipulation. However, achieving high performance and low energy consumption when running complex DNNs can be tough without specialized accelerators, which are both costly and intricate to create. To address this, there’s a growing need for affordable and efficient hardware design solutions. This has spurred numerous research initiatives aimed at developing adaptable and modular hardware generators for DNN accelerators and other hardware components.
While hardware generator initiatives simplify the creation of DNN accelerators, they often concentrate solely on designing the accelerator component. This overlooks system-level factors crucial for the overall system-on-chip (SoC) and complete software stack. Certain industry viewpoints advocate for a comprehensive approach to DNN accelerator development and deployment. However, current DNN generators lack robust support for a complete programming interface covering both high and low-level accelerator control, as well as limited support for full SoC integration. This deficiency makes it difficult to assess system-level impacts accurately.
In this study, Gemmini is introduced as an open-source DNN accelerator generator designed for DNN workloads. It facilitates end-to-end implementation and evaluation of custom hardware accelerator systems for rapidly evolving DNN tasks. Gemmini’s hardware template and parameterization empower users to fine-tune hardware design options across performance, efficiency, and extensibility parameters. In contrast to existing DNN accelerator generators that focus solely on standalone accelerators, Gemmini provides a comprehensive solution covering both hardware and software stacks, as well as complete SoC integration compatible with the RISC-V ecosystem. Additionally, Gemmini implements a multi-level software stack with a user-friendly programming interface catering to diverse programming requirements, and it seamlessly integrates with Linux-capable SoCs, allowing execution of any arbitrary software.
Gemmini-generated accelerators have been successfully produced using both TSMC 16nm FinFET and Intel 22nm FinFET Low Power (22FFL) process technologies, demonstrating their viability. Evaluation results indicate that Gemmini-generated accelerators achieve performance levels comparable to those of leading commercial DNN accelerators under similar hardware configurations, boasting up to a 2,670x speedup compared to a baseline CPU. The integrated, full-stack approach of Gemmini enables users to concurrently design the accelerator, application, and system, thereby presenting new avenues for research in deep learning System-on-Chip (SoC) integration. Through case studies utilizing Gemmini, it is demonstrated how designers can optimize virtual address translation mechanisms and memory resource partitioning to cater to diverse compute requirements across different layers within a DNN.
In essence, this work presents three key contributions. Firstly, the development of Gemmini, an open-source infrastructure for designing full-stack DNN accelerators. Gemmini offers a flexible hardware template, a multi-layered software stack, and an integrated SoC environment, enabling systematic evaluation of deep learning architectures. Secondly, rigorous evaluation of Gemmini-generated accelerators is conducted using FPGA-based performance measurement and commercial ASIC synthesis flows. The evaluation demonstrates comparable performance to state-of-the-art commercial DNN accelerators. Lastly, the study showcases Gemmini’s capacity for system-accelerator co-design in SoCs executing DNN workloads. This involves designing efficient virtual-address translation schemes for DNN accelerators and managing memory resources in a shared cache hierarchy.
Results
Evaluation Methodology
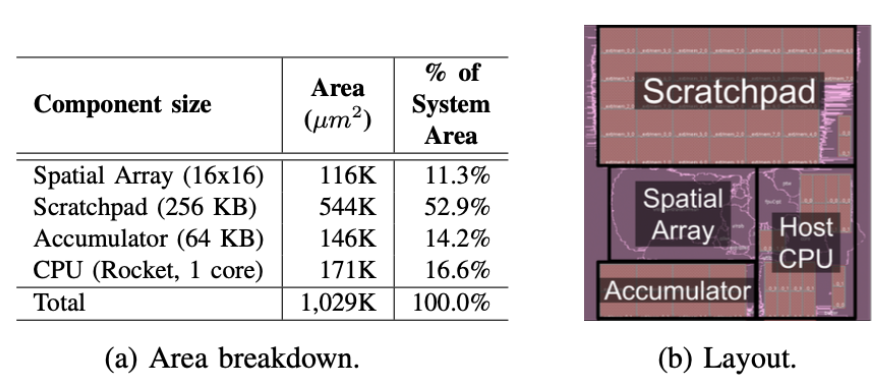
The end-to-end performance evaluation of Gemmini-generated accelerators is conducted using the FireSim FPGA-accelerated simulation platform. Five popular DNNs, including ResNet50, AlexNet, SqueezeNet v1.1, MobileNetV2, and BERT, are evaluated within a complete cycle-exact simulated SoC environment running a full Linux setup. Designs are synthesized using Cadence Genus with the Intel 22nm FFL process technology and then placed-and-routed using Cadence Innovus. The breakdown of layout and area, outlined in Figure 1, indicates that SRAMs alone consume 67.1% of the accelerator’s total area. The spatial array occupies merely 11.3% of the area, while the host CPU accounts for a higher 16.6% of the area.
Performance Results
The study evaluated several configurations of Gemmini, each featuring different host CPUs and optional compute blocks, to investigate their impact on end-to-end performance. Two host CPUs were considered: a low-power in-order Rocket core and a high-performance out-of-order BOOM core. Additionally, two Gemmini configurations were examined: one without an on-the-fly im2col block and the other with this block, which shifts im2col operations from the host CPU to the accelerator.
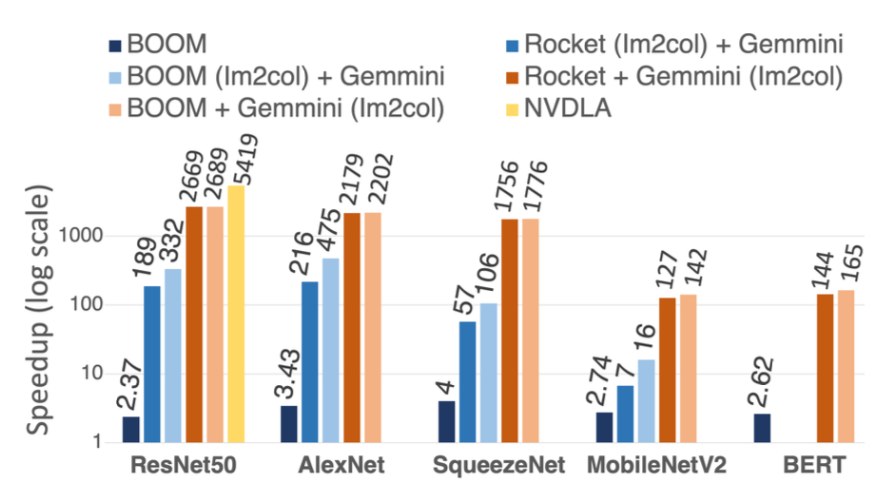
In configurations without an on-the-fly im2col unit, the overall performance heavily depends on the host CPU’s capabilities as it handles im2col operations during CNN inference. A larger out-of-order BOOM CPU improves performance by 2\(\times\) across all CNNs. Conversely, when the accelerator includes an on-the-fly im2col unit, the choice of host CPU becomes less critical as more computational tasks are offloaded to the accelerator. This allows for a simpler in-order core in the host CPU while maintaining performance. Gemmini provides hardware designers with the flexibility to navigate these performance-efficiency tradeoffs. (Figure 2)
With the on-the-fly im2col unit and a basic in-order Rocket CPU, Gemmini achieves significant performance gains, such as 22.8 frames per second (FPS) for ResNet50 inference at 1 GHz—a 2,670\(\times\) speedup over the in-order Rocket CPU and a 1,130\(\times\) speedup over the out-of-order BOOM CPU. Additionally, Gemmini achieves 79.3 FPS on AlexNet. While some DNN models like MobileNetV2 may not efficiently utilize spatial accelerators due to low data reuse in depthwise convolution layers, Gemmini still achieves a 127\(\times\) speedup over the Rocket host CPU, reaching 18.7 FPS at 1 GHz. On SqueezeNet, designed for efficient CPU operation while conserving memory bandwidth, Gemmini demonstrates a 1,760\(\times\) speedup over the Rocket host CPU. These results are consistent with other accelerators like NVDLA under similar configurations. For language models like BERT, Gemmini achieves a 144\(\times\) improvement over the Rocket CPU.
Critical Review
Pros
- Gemmini offers a full-stack solution for generating DNN accelerators, including flexible architectural templates, software flows, and complete SoC integration, providing a holistic approach to accelerator design.
- Being open-source, Gemmini fosters collaboration and allows researchers and developers to access and modify the tool according to their needs.
- The paper demonstrates systematic evaluations of Gemmini-generated accelerators, showcasing their high performance efficiency and providing insights into co-design and system-level behavior evaluation.
Cons
- While Gemmini demonstrates high performance efficiency, the paper may lack extensive comparisons with other existing DNN accelerator generators or commercial solutions, which could provide more context for its performance.
- Power metrics for the fabricated processors are not provided in the paper.
Takeaways
Gemmini is introduced as a comprehensive, open-source tool for generating DNN accelerators, facilitating systematic evaluations of their architectures. It utilizes a flexible architectural template to accommodate various types of DNN accelerator designs. Gemmini also offers a user-friendly, high-level software flow to enhance programmer efficiency. Furthermore, it generates complete SoCs capable of running real-world software stacks, including operating systems, enabling thorough evaluation of system-level impacts by system architects. Our evaluation indicates that Gemmini-generated accelerators exhibit high performance efficiency. Case studies demonstrate how accelerator designers and system architects can utilize Gemmini to co-design and assess system-level behavior in emerging applications.
References
- H. Genc, S. Kim, A. Amid, A. Haj-Ali, V. Iyer, P. Prakash, J. Zhao, D. Grubb, H. Liew, H. Mao, A. Ou, C. Schmidt, S. Steffl, J. Wright, I. Stoica, J. Ragan-Kelley, K. Asanovic, B. Nikolic, and Y. S. Shao, “Gemmini: Enabling systematic deep-learning architecture evaluation via full-stack integration,” 2021.