
Research Paper Review: Eyeriss - A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks
In this paper, the researchers introduce a novel dataflow technique termed row-stationary (RS), aimed at minimizing energy consumption related to data movement in spatial architectures. RS achieves this by optimizing local data reuse of filter weights and feature map pixels, thereby reducing data movement in high-dimensional convolutions, as well as minimizing the movement of partial sum accumulations. Unlike existing dataflow methods that target specific types of data movement, RS is designed to adapt to various CNN configurations, thereby reducing all forms of data movement through efficient utilization of processing engine (PE) local storage, direct inter-PE communication, and spatial parallelism. To assess energy efficiency, the authors propose a framework for comparing energy costs under consistent hardware area and processing parallelism constraints. Experimental results using the AlexNet CNN configurations demonstrate that RS outperforms existing dataflows, achieving energy savings of 1.4\(\times\) to 2.5\(\times\) in convolutional layers and at least 1.3\(\times\) in fully-connected layers for batch sizes larger than 16. The energy efficiency of RS is further validated through its implementation on a fabricated chip, confirming the findings of the energy analysis.
Paper Summary
The recent surge in popularity of deep learning, particularly deep convolutional neural networks (CNNs), owes to their remarkable accuracy across tasks like object recognition, detection, and scene understanding. These advanced CNNs, significantly larger than those of the 1990s, demand substantial storage for filter weights and involve thousands of operations per input pixel.
However, the sheer size of these networks presents challenges for processing hardware, particularly in terms of throughput and energy efficiency. Convolutions, which make up over 90% of CNN operations, dominate runtime. While highly-parallel compute paradigms like SIMD/SIMT can help, scaling throughput is hindered by bandwidth constraints, and energy consumption remains high due to the costly data movement.
To tackle these challenges, there’s a need for dataflows that support parallel processing with minimal data movement. It’s crucial to consider the energy cost differences associated with data storage locations, such as off-chip DRAMs versus on-chip storage.
Various specialized CNN dataflows have been proposed in previous literature, targeting platforms like GPU, FPGA, and ASIC. However, direct comparisons between implementations lack insight into relative energy efficiency due to differences in technology and setup. This paper evaluates the energy efficiency of different CNN dataflows on a spatial architecture under consistent hardware constraints, proposing a novel dataflow that maximizes energy efficiency for CNN acceleration.
To assess energy consumption, the paper categorizes data movements in a spatial architecture into hierarchical levels based on their energy cost and analyzes each dataflow accordingly. This framework offers insights into how different dataflows leverage architecture resources and provides a quantifiable means to compare energy efficiency.
Unlike previous dataflows that optimize specific types of data movement, the proposed approach exploits all forms of data reuse and considers energy costs at different storage hierarchy levels, resulting in significant energy savings. The main contributions of the work include a taxonomy for classifying existing CNN dataflows, the introduction of a spatial architecture based on a new optimized CNN dataflow, an analysis framework for quantifying energy efficiency, and a comparative analysis of energy costs and data reuse impact across various CNN dataflow.
Spatial Architecture
Spatial architectures (SAs) are specialized accelerators that exploit high compute parallelism by directly communicating between a grid of simple processing engines (PEs). They’re flexible and can support various algorithms through specialized dataflows. SAs excel for applications with producer-consumer relationships or efficient data sharing among PEs.
There are two types of SAs: coarse-grained SAs, consisting of tiled arrays of ALU-style PEs connected via on-chip networks, and fine-grained SAs, typically in FPGA form. Coarse-grained SAs are popular for specialized CNN accelerators due to their ability to handle uniform operations with high parallelism and effective inter-PE communication for distributed accumulation or parallel computation without costly data transfers.
The challenge lies in mapping the CNN dataflow to the SA, impacting throughput and energy efficiency. The SA system comprises a global buffer, PE array, and off-chip DRAM interconnected via input and output FIFOs. The global buffer aids input data reuse and latency hiding, while the PEs feature ALU datapaths, register files, and PE FIFOs. Different dataflows require varying RF sizes, affecting overall storage hierarchy, with DRAM access being most costly and RF access being the least.
This paper’s accelerator system for CNN processing integrates a SA accelerator and off-chip DRAM. Inputs are loaded from CPU or GPU to DRAM, processed by the accelerator, and outputted back to DRAM for interpretation by the main processor. The system aims to optimize data movement and processing efficiency across its hierarchical storage levels.
CNNs
A convolutional neural network (CNN) is a stack of computation layers arranged in a directed acyclic graph. Each layer extracts a higher-level abstraction of the input data, called a feature map (fmap), to preserve crucial information. Modern CNNs achieve exceptional performance by incorporating a deep hierarchy of layers.
The primary computation in CNNs occurs in convolutional (CONV) layers, where high-dimensional convolutions are performed. CNN models commonly use five to several hundred CONV layers, applying filters on input fmaps to extract visual characteristics and produce output fmaps. Both filters and fmaps have 4D dimensions, comprising multiple 2D planes or channels. Additionally, fully-connected (FC) layers, typically a small number, are stacked behind CONV layers for classification. Each FC layer applies filters on input fmaps, but unlike CONV layers, the filters match the size of the fmaps and lack weight sharing. Intermediate layers like pooling (POOL) and normalization (NORM) layers may be added between CONV and FC layers, each followed by an activation (ACT) layer.
In widely used CNNs like AlexNet and VGG16, CONV layers contribute over 90% of overall operations and generate significant data movement. However, recent studies show that the weight data in FC layers can be highly compressed, minimizing their impact. Pooling layers share the same compute scheme as CONV layers, while ACT layers’ computation is straightforward. Processing CONV and FC layers faces challenges in data handling and adaptive processing.
Data handling involves efficiently managing input data and intermediate results. Exploiting various types of input data reuse—convolutional, filter, and ifmap reuse—helps alleviate bandwidth and energy consumption issues. Proper operation scheduling reduces the storage pressure caused by generating simultaneous partial sums (psums) and saves memory energy.
Adaptive processing deals with accommodating the myriad of CONV/FC layer shapes dictated by various CNN models. The hardware architecture must be programmable to dynamically adapt to different shapes, ensuring efficient dataflow for CNN processing.
Before CNNs gained prominence, research focused on efficient convolution techniques for image signal processing (ISP). However, these techniques are not directly applicable to CNN processing due to differences in filter weights’ origin, data dimensions, and psum accumulation complexities.
Existing CNN Dataflows
Previous studies have proposed various solutions for accelerating CNNs, but comparing their performance directly is challenging due to differences in implementation and design choices. This section introduces a taxonomy of existing CNN dataflows based on how they handle data.
Weight Stationary (WS) Dataflow
In this approach, each filter weight remains stationary in the RF (Register File) to maximize convolutional and filter reuse. The weights from the same filter and channel are laid out to a region of PEs and remain stationary. Each pixel in an input fmap plane from the same channel is sequentially broadcast to the same PEs, and the resulting psums are spatially accumulated across these PEs. The RF stores the stationary filter weights. Psums may not be immediately reducible due to operation scheduling, requiring temporary storage to the global buffer.
Output Stationary (OS) Dataflow
In this approach, the accumulation of each output fmap pixel stays stationary in a PE, with psums stored in the same RF to minimize accumulation cost. This dataflow processes a region of the 4D output fmap at a time, with choices for multiple or single output fmap channels and pixels, resulting in subcategories like SOC-MOP, MOC-MOP, and MOC-SOP. RF stores psums for stationary accumulation. SOC-MOP and MOC-MOP may need additional RF storage for ifmap buffering to exploit convolutional reuse.
No Local Reuse (NLR) Dataflow
This approach doesn’t exploit data reuse at the RF level and uses inter-PE communication for ifmap reuse and psum accumulation. PEs within the same group read the same ifmap pixel with different filter weights from the same input channel. Different PE groups read ifmap pixels and filter weights from different input channels, with psums accumulated across PE groups. No RF storage is required. Special registers at the end of each PE array column hold the psums, reducing global buffer R/W for psums.
Energy-efficient Dataflow: Row Stationary
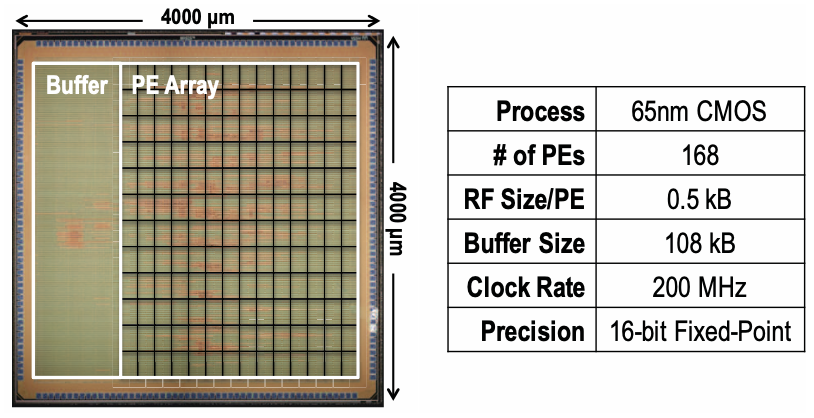
Existing dataflows attempt to optimize specific types of input data reuse or minimize psum accumulation costs, but they often overlook other factors, leading to inefficiencies when layer shapes or hardware resources vary. To address this, a novel dataflow called row stationary (RS) is introduced, which is a key feature of the Eyeriss architecture. This dataflow has been validated with AlexNet on a fabricated chip. (Figure 1)
1D Convolution Primitives
The RS dataflow divides high-dimensional convolutions into 1D primitives that run in parallel, each operating on one row of filter weights and ifmap pixels to produce one row of psums. These psums are then accumulated to generate output fmap pixels.
Two-Step Primitive Mapping
Primitive mapping involves logical and physical steps. Logical mapping assigns primitives to a logical PE array, while physical mapping folds this array to fit into the physical PE array. Folding is determined by on-chip storage constraints and aims to exploit input data reuse and psum accumulation.
Energy-Efficient Data Handling
The RS dataflow optimizes all types of data movement by maximizing storage hierarchy usage, from low-cost RF to higher-cost array and global buffer. Each level handles data with specific optimizations.
Support for Different Layer Types
RS naturally supports FC and POOL layers, adapting hardware resources to cover filter reuse, ifmap reuse, and psum accumulation without needing to switch between dataflows.
Other Architectural Features
The Eyeriss architecture employs separate NoCs for ifmaps, filters, and psums, along with sparsity techniques to further reduce data movement and energy consumption.
This efficient dataflow, combined with architectural features, enhances energy efficiency and performance in CNN processing.
Experiment Methodology
Dataflow Implementation: A simulation model for each dataflow is implemented to analyze energy efficiency using a proposed framework. The RS dataflow model is compared with various existing dataflow variants. These variants aim to capture key characteristics common across different designs:
- Weight Stationary (WS):
- Each PE stores a single weight in the RF at a time.
- Psums generated in a PE are either passed to neighboring PEs or stored in the global buffer.
- The PE array operates as a systolic array with minimal local control, allowing for a large global buffer crucial for WS dataflow.
- Output Stationary (OS):
- Each PE accumulates psums for a single ofmap pixel.
- Variants like MOC-MOP OS dataflow exploit convolutional and ifmap reuse, offering improved performance over plain matrix multiplication implementations.
- No Local Reuse (NLR):
- The PE array comprises only ALU datapaths without local storage.
- All data, including ifmaps, filters, and psums, are stored in the global buffer.
Dataflow Comparison Setup: To compare performance, constraints are imposed on fixed hardware area and processing parallelism for all dataflows. This ensures each dataflow has the same number of PEs with equivalent storage area, including the global buffer and RF. The allocation between global buffer and RF varies based on dataflow storage requirements. For example, RS may allocate a larger RF for better data reuse, while NLR does not require an RF at all.
Framework for Energy Efficiency Analysis: The analysis aims to optimize dataflows for spatial architectures by considering energy costs of data accesses and psum accumulation. It defines energy costs for each storage hierarchy level and provides a methodology to quantify overall data movement energy cost. The framework incorporates input data access and psum accumulation energy costs, taking into account layer shape and hardware resources.
- Data Movement Hierarchy: The SA accelerator offers four storage hierarchy levels: DRAM, global buffer, array, and RF, with varying energy costs for data accesses. Energy costs are quantified by counting accesses to each level and weighting them with predefined costs.
- Analysis Methodology: For each dataflow, the analysis splits data reuse and accumulation across the storage hierarchy levels to estimate energy costs. Parameters describing optimal mappings for energy efficiency under given CNN layer shapes are obtained through optimization constrained by hardware resources.
Dataflow Modeling Considerations: While charging the same energy cost at each storage hierarchy level across dataflows, real costs may vary due to implementation differences. Factors such as global buffer size, array transfer distances, and RF size impact energy costs, with certain dataflows experiencing more significant effects. Overall, the results aim to provide conservative estimates for RS compared to other dataflows.
Results
The simulation of the RS dataflow is compared with the implementation of existing dataflows while adhering to the same hardware area and processing parallelism constraints. Utilizing the framework, the mapping for each dataflow is optimized to maximize energy efficiency. AlexNet serves as the chosen CNN model for benchmarking due to its widespread adoption. With its 5 CONV and 3 FC layers, AlexNet offers a diverse set of shapes suitable for evaluating different dataflows’ adaptability. The simulations assume a word size of 16 bits, and results aggregate data from all CONV or FC layers in AlexNet. For clarity, the SOC-MOP, MOC-MOP, and MOC-SOP OS dataflows are respectively denoted as OSA, OSB, and OSC.
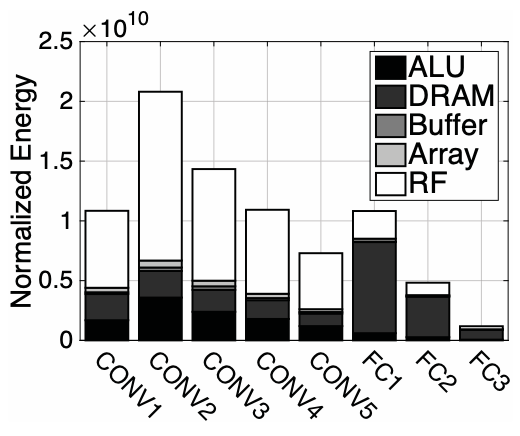
RS Dataflow Energy Consumption: Simulations of the RS dataflow are conducted with the following specifications: (1) 256 PEs, (2) 512 bytes (B) of RF per PE, and (3) a 128kB global buffer. A batch size of 16 is fixed. Figure 2 illustrates the breakdown of energy consumption across the storage hierarchy in both the 5 CONV and 3 FC layers of AlexNet. Energy values are normalized to a single ALU operation, such as a MAC operation.
Distinct energy distributions are observed between the two types of layers. For CONV layers, RF accesses dominate energy consumption, indicating that the RS dataflow effectively leverages various types of data movement within the local RF while minimizing accesses to higher-cost storage levels. This finding is corroborated by measurements from the Eyeriss chip, where the energy ratio of RF accesses to other levels (excluding DRAM) is approximately 4:1. Conversely, in FC layers, energy consumption is primarily driven by DRAM accesses due to the absence of convolutional data reuse. Nonetheless, CONV layers still account for roughly 80% of the total energy consumption in AlexNet. This proportion is anticipated to increase further in modern CNN architectures featuring a greater number of CONV layers.
Dataflow Comparison in CONV Layers:
- DRAM Accesses:
- DRAM accesses have a significant impact on overall energy efficiency due to their higher energy cost compared to on-chip data movements.
- RS, OSA, OSB, and NLR demonstrate lower DRAM accesses compared to WS and OSC, indicating better on-chip data reuse.
- WS prioritizes weight reuse but lacks ifmap reuse, leading to high DRAM accesses due to limitations in filter loading and global buffer size.
- All dataflows benefit from larger hardware area and higher parallelism to reduce DRAM accesses, with significant improvements observed for WS and OSC.
- Energy Consumption:
- RS exhibits 1.4\(\times\) to 2.5\(\times\) higher energy efficiency compared to other dataflows by fully leveraging the lowest-cost data movement at the RF for all data types.
- OSA, OSB, and NLR, despite similar or lower DRAM accesses, consume more total energy due to their reliance on higher-cost data movement.
- RS optimizes energy consumption for all data types simultaneously, unlike other dataflows that prioritize specific types of data movement.
- Energy consumption per operation remains relatively stable across dataflows with scaled-up hardware area and parallelism, except for WS, which benefits from a larger global buffer size.
- Energy-Delay Product (EDP):
- EDP analysis confirms that high energy efficiency is not achieved at the expense of processing parallelism.
- RS demonstrates the lowest EDP due to its efficient utilization of available PEs with 1D convolution primitives.
- OSA and OSC exhibit high EDP at a batch size of 1 due to low PE utilization, especially with larger array sizes.
In summary, RS dataflow outperforms existing dataflows in terms of energy efficiency, leveraging on-chip data reuse effectively while maintaining processing parallelism.
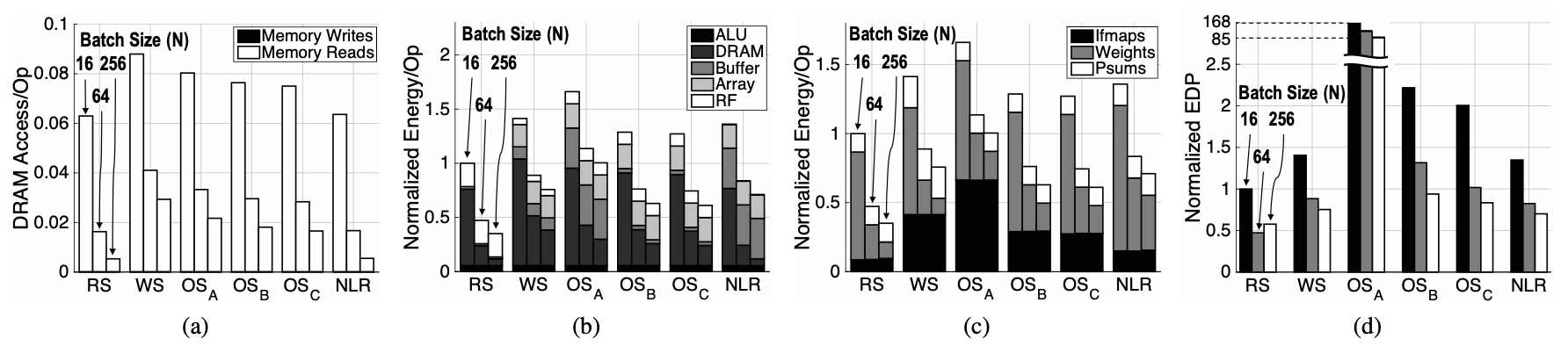
Dataflow Comparison in CONV Layers: In the experiments conducted for the FC layers of AlexNet, depicted in Figure 3, all dataflows were evaluated under a PE array size of 1024. Similar trends were observed for other PE array sizes. Batch sizes began from 16 since minimal data reuse occurred with a batch size of 1, resulting in DRAM accesses dominating energy consumption for weights across all dataflows, with approximately equal energy consumption. However, techniques like pruning and quantization of values can reduce DRAM accesses. Among the evaluated dataflows, RS demonstrated the lowest DRAM accesses, energy consumption, and EDP in the FC layers. Increasing batch size improved energy efficiency for all dataflows due to increased filter reuse. Yet, the gap widened between RS and WS/OS dataflows because their energy was predominantly consumed by ifmap accesses.
Specifically, OSA struggled with FC layers due to its mapping, which necessitates ifmap pixels from the same spatial plane, a mismatch with the typically small spatial size of FC layers. Overall, RS proved to be at least 1.3\(\times\) more energy efficient than other dataflows at a batch size of 16, and potentially up to 2.8\(\times\) more energy efficient at a batch size of 256.
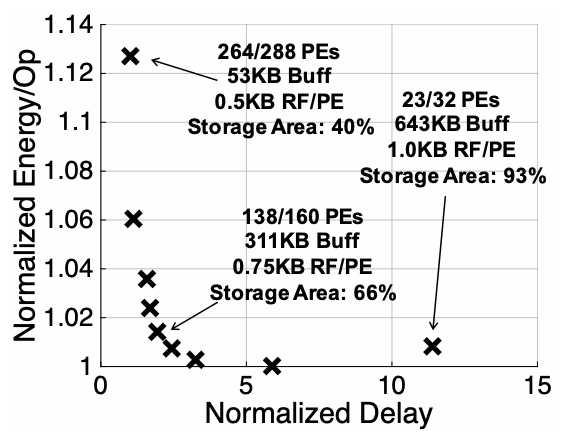
Hardware Resource Allocation for RS: In investigating hardware resource allocation for the RS dataflow, researchers vary the distribution between processing and storage within a fixed area to assess its impact on energy efficiency and throughput. Utilizing a setup with 256 PEs and baseline storage area they adjust the number of PEs from 32 to 288 while modifying the size of RF and global buffer to minimize energy cost in the CONV layers of AlexNet for each configuration.
Figure 4 illustrates the normalized energy and processing delay for different resource allocations. Notably, increasing the number of PEs boosts throughput by over 10\(\times\), with a mere 13% increase in energy cost. This phenomenon arises from the heightened data reuse opportunities facilitated by a larger PE array. However, the trade-off between throughput and energy isn’t linear: too small a PE array yields lower energy efficiency due to minimal data reuse and a sufficiently large global buffer that further increases doesn’t significantly enhance data reuse.
Critical Review
Pros
- The paper introduces a novel dataflow called row stationary (RS), which aims to minimize energy consumption by maximizing input data reuse and minimizing partial sum accumulation cost. This innovative approach offers a promising solution for improving energy efficiency in CNN processing.
- A comprehensive analysis framework is presented to evaluate the energy cost of different CNN dataflows on spatial architectures. This framework considers various factors such as storage hierarchy levels, fixed area constraints, and processing parallelism, providing a thorough understanding of energy efficiency factors.
- The proposed RS dataflow is empirically validated against existing dataflows using AlexNet as a benchmark. The experimental results demonstrate the superior energy efficiency of the RS dataflow compared to other approaches in both convolutional and fully-connected layers.
- Scalability analysis is conducted by varying hardware resources such as the number of processing elements (PEs) and batch sizes. This analysis provides insights into the impact of hardware resource allocation on energy efficiency and processing throughput.
Cons
- The paper primarily focuses on benchmarking against AlexNet, which may limit the generalizability of the findings. Including a broader range of CNN models or real-world applications could strengthen the validity of the results.
- Some of the assumptions made in the analysis, such as fixed area constraints and simplified DRAM access models, may oversimplify the real-world scenario. Addressing these simplifications could provide a more accurate assessment of energy efficiency.
- Implementing the proposed RS dataflow or replicating the analysis framework may require substantial effort and expertise in spatial architecture design and optimization. This complexity could hinder practical adoption by researchers or engineers.
Takeaways
This paper introduces an analysis framework for assessing the energy efficiency of various CNN dataflows on spatial architectures. It considers energy costs across different storage hierarchy levels under fixed area and processing parallelism constraints. Moreover, it facilitates the search for the most energy-efficient mapping for each dataflow.
Within this framework, a new dataflow called row stationary (RS) is proposed. RS minimizes energy consumption by maximizing input data reuse (filters and feature maps) and minimizing partial sum accumulation cost simultaneously, while also considering the energy cost of different storage levels. Compared to existing dataflows like output stationary (OS), weight stationary (WS), and no local reuse (NLR) using AlexNet as a benchmark, RS proves to be 1.4\(\times\) to 2.5\(\times\) more energy efficient in convolutional layers and at least 1.3\(\times\) more energy efficient in fully-connected layers for batch sizes of at least 16.
Furthermore, it’s noted that DRAM bandwidth alone doesn’t solely dictate energy efficiency. Dataflows requiring high on-chip global buffer bandwidth can also lead to significant energy costs. Increasing the size of the PE array improves processing throughput for all dataflows with similar or better energy efficiency. Larger batch sizes also enhance energy efficiency in all dataflows except for WS, which suffers from inadequate global buffer size. Lastly, for the RS dataflow, the allocation of area between processing and storage has limited impact on energy efficiency due to the improved data reuse with more PEs, balancing out the effect of reduced on-chip storage.
References
- Y. H. Chen, J. Emer, and V. Sze, “Eyeriss: a spatial architecture for energy-efficient dataflow for convolutional neural networks,” SIGARCH Comput. Archit. News, vol. 44, no. 3, p. 367–379, jun 2016. [Online]. Available: https://doi.org/10.1145/3007787.3001177