
Research Paper Review: Dark Silicon and the End of Multicore Scaling
The paper models multicore scaling limits to measure the speedup potential for parallel workloads for the next five technology generations. The findings indicate that irrespective of the chip organization and configuration, the ability of multicore scaling to enhance performance is ultimately restricted by power limitations.
Paper Summary
The failure of Dennard scaling and slowed voltage scaling raises concerns about the scalability of increasing core counts, leaving uncertainty about leveraging continued transistor count growth. Despite power limitations in future designs, higher core counts must still deliver performance improvements, considering the challenges of worsening energy and speed scaling of transistors and the available parallelism in applications. By examining these factors collectively, we can estimate the potential benefits of multicore scaling across additional technology generations. However, since device energy efficiency isn’t keeping pace with integration capacity and few applications can efficiently utilize a large number of cores, understanding the long-term viability of multicore performance is crucial. The study must consider various factors such as devices, core microarchitectures, chip organizations, and benchmark characteristics while applying area and power limits at each technology node. This paper integrates these factors to project the upper-bound performance achievable through multicore scaling, assessing the impact of non-ideal device scaling, including the percentage of “dark silicon,” and making additional projections regarding optimal core organization, chip-level topology, and the ideal number of cores.
The paper considers technology scaling projections, single-core design scaling, multicore design choices, actual application behavior, and microarchitectural features together. While previous studies have analyzed these features individually or in partial combinations, this study integrates them comprehensively. It builds and combines three models:
- Device scaling model (\(DevM\)) forecasts area, frequency, and power requirements at future technology nodes up to 2024.
- Core scaling model (\(CorM\)) establishes power/performance and area/performance single core Pareto frontiers from a wide array of microprocessor designs.
- Multicore scaling model (\(CmpM\)) evaluates area, power, and performance of any application for both CPU-like and GPU-like multicore configurations.
- \(DevM \times CorM\) generates Pareto frontiers at future technology nodes, where any performance enhancements for future cores will incur costs in terms of area or power as dictated by these curves.
- \(CmpM \times DevM \times CorM\) conducts an exhaustive state-space search to determine the maximum multicore speedups for future technology nodes while adhering to area, power, and benchmark constraints.
The paper’s findings offer detailed insights into the best-case scenarios for multicore performance improvements in future technologies, based on real applications from the PARSEC benchmark suite. The evaluation of these benchmarks, along with an upper-bound analysis, confirms several key points:
- Despite common beliefs about the benefits of multicore usage, the study suggests that over five technology generations, the average speedup achievable through ITRS scaling is limited to just 7.9 times.
- As transistor sizes continue to shrink, power constraints hinder the utilization of chip space. By 22 nm (around 2012), it is projected that 21% of the chip will remain unused, and at 8 nm, over 50% of the chip will go unutilized, according to ITRS scaling predictions.
- Neither CPU-like nor GPU-like multicore designs are projected to meet the anticipated levels of performance speedup. The paper suggests that radical microarchitectural innovations are necessary to modify the power/performance Pareto frontier and achieve speedups consistent with Moore’s Law.
Results
The paper investigates the primary source of dark silicon by conducting experiments varying power and parallelism levels independently. At the 8nm node (2018), they first set power as the sole constraint and adjust parallelism levels in PARSEC applications. Results show that increasing parallelism yields only modest performance improvements, with most benchmarks reaching a speedup of around 15× at 99% parallelism. Even under ideal parallelism conditions, typical ITRS-scaling speedups remain limited to 15×, and with conservative scaling, the best-case speedup is 6.3×. Next, they examine the scenario where parallelism alone is constrained, allowing the power budget to range from 50 W to 500 W (default is 125 W). This analysis reveals that parallelism is the primary contributor to dark silicon, as only four benchmarks possess adequate parallelism to potentially sustain Moore’s Law level speedup, while power limitations constrain the rest.
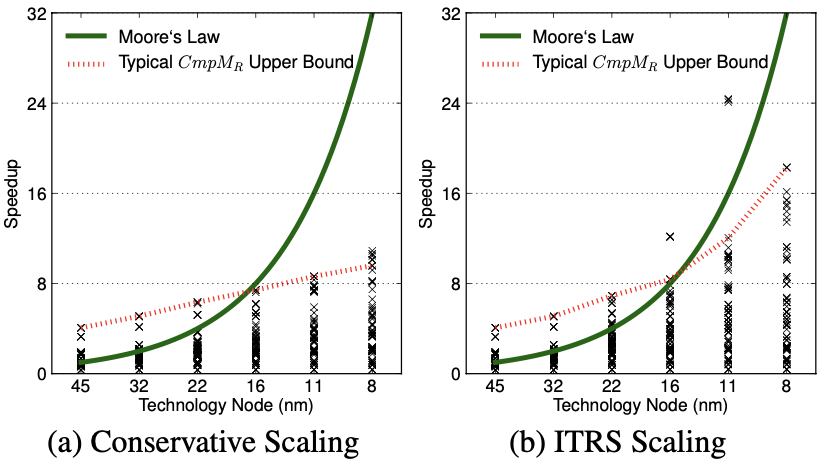
Figure 1 presents a scatter plot summarizing all speedup projections. Each benchmark at every technology node is represented, with eight possible configurations: (CPU, GPU) × (symmetric, asymmetric, dynamic, composed). A solid curve illustrates Moore’s Law performance, indicating a doubling of performance with each technology node. However, due to power and parallelism constraints, there’s a significant gap between achievable speedups and Moore’s Law expectations. Although results for ITRS scaling show slight improvement, the gap remains substantial. With conservative scaling, the speedup gap is at least 22 times at the 8 nm technology node compared to Moore’s Law. Assuming ITRS scaling, the gap reduces to at least 13 times at 8 nm.
The paper acknowledges several limitations in its modeling approach, arguing that these limitations do not significantly alter the results. SMT (Simultaneous Multithreading) support for CPU cores was not considered, which can enhance power efficiency for parallel workloads to some extent. The study examined 2-way, 4-way, and 8-way SMT scenarios, noting varying speedup outcomes. Additionally, the GPU methodology might overestimate the GPU power budget, prompting an investigation into the impact of improved energy efficiency. The paper does not account for the power impact of “uncore” components like the memory subsystem, which could further reduce speedups as their numbers increase. ARM or Tilera cores were excluded from the analysis due to differences in application domains and lack of SPECmark scores for comparison. Despite these assumptions, the paper asserts its validation against real and simulated systems consistently under-predicts performance, suggesting a conservative approach to parameter selection.
Critical Review
Pros
- Comprehensive Analysis: The paper combines technology scaling models, performance models, and empirical results from parallel workloads to provide a thorough examination of the remaining performance potential from multicore scaling.
- Critical Evaluation: The paper critically evaluates the limitations and challenges of multicore scaling, highlighting potential discrepancies in optimistic projections and proposing more conservative models to align with recent trends.
Cons
- Simplified Assumptions: While the paper aims to provide a comprehensive analysis, it may oversimplify certain aspects of multicore scaling and technological projections, potentially overlooking nuances that could impact the accuracy of the findings.
- Limited Scope: The analysis primarily focuses on multicore scaling and its implications, which may neglect other emerging technologies or architectural approaches that could also contribute to future performance gains.
- Uncertainty in Projections: The paper acknowledges uncertainties in projections, particularly regarding the accuracy of ITRS projections and the feasibility of achieving ideal performance gains in practice, which may limit the reliability of its conclusions.
Takeaways
For decades, Dennard scaling allowed for more, faster, and energy-efficient transistors with each new process node, supporting Moore’s Law. However, its failure pushed the industry towards multicore architectures, initially providing scaling benefits. But as multicore advantages diminish, finding new ways to boost transistor utility is crucial to sustaining Moore’s Law. This paper combines various models and data to assess multicore scaling’s remaining potential. While optimistic projections suggest significant gains, the paper argues for a more conservative outlook based on recent trends. It warns that relying solely on multicore scaling may not justify continued process scaling. If multicore scaling fades, it could mark a short-lived era, necessitating innovative architectures to maintain progress. The future will likely require groundbreaking ideas from computer architects
References
- H. Esmaeilzadeh, E. Blem, R. S. Amant, K. Sankaralingam, and D. Burger, “Dark silicon and the end of multicore scaling,” in 2011 38th Annual International Symposium on Computer Architecture (ISCA), 2011, pp. 365–376.