
Research Paper Review: Characterizing and Optimizing End-to-End Systems for Private Inference
In two-party machine learning prediction services, clients seek to utilize a remote server’s trained machine learning model without exposing sensitive data. This necessity gave rise to Private Inference (PI) protocols, which aim to maintain confidentiality for both client data and server models. However, current PI methods are slow and not widely comprehended. This paper aims to enhance PI by thoroughly examining a high-performance protocol. They identify inefficiencies in computation, communication, and storage. Unlike previous studies, they consider the arrival rates of inference requests, demonstrating the significance of the pre-processing phase, which often necessitates online execution due to limited downtime. Based on the findings, they propose three optimizations: Client-Garbler to reduce storage overhead, layer-parallel HE to enhance computation, and wireless slot allocation to improve communication. These optimizations increase PI speed by 1.8\(\times\) and enable handling 2.24\(\times\) more inference requests compared to current methods.
Paper Summary
As users increasingly demand more control over their data usage, privacy becomes paramount. This affects popular cloud services heavily reliant on precise user data. One solution is leveraging privacy-preserving computation to ensure user data’s privacy and security throughout the entire execution pipeline, not just communication. This approach provides improved privacy and security while enabling the use of essential online services.
AI, being central to data processing, is a natural fit for privacy-preserving computing. However, current methods are still impractical. Privacy-preserving techniques vary in security achievement, including system implementation, statistics, and cryptography. While systems solutions offer performance, they are less secure. Statistical methods like differential privacy offer stronger privacy but can reduce accuracy. Cryptography-based solutions provide exact inferences but with high overheads.
Research on private inference (PI) using cryptography-based methods like homomorphic encryption (HE) and secure multi-party computation (MPC) is extensive. Most protocols adopt a hybrid approach tailored to different network layers’ computational needs. Recent efforts focus on protocol optimization and hardware acceleration but lack a holistic approach.
This paper presents the first comprehensive characterization of end-to-end private inference using state-of-the-art hybrid protocols. It considers both online and offline phases and accounts for compute, communication, and storage overheads. Unlike prior work, it examines inference request arrival rates rather than individual inferences, revealing significant offline costs that cannot always remain offline.
The characterization identifies crucial insights:
- The offline phase’s computation time is substantial, involving computations running on the order of minutes.
- Hybrid protocols incur large offline storage costs, overwhelming client device storage.
- ReLUs introduce significant communication and computation overheads.
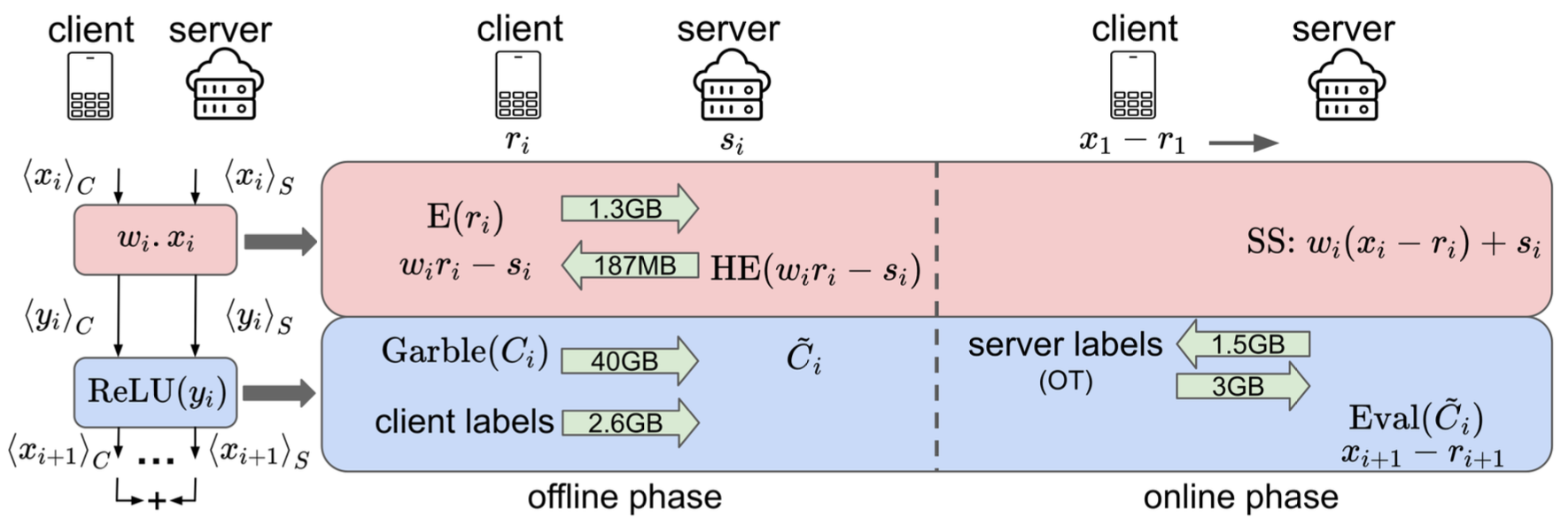
Leveraging these insights, the paper proposes three optimizations to improve inference latency: Client-Garbler protocol (Figure 1) to address client storage limits, layer-parallel HE to reduce computational costs, and wireless slot allocation for efficient communication. These optimizations collectively improve mean inference latency by 1.8\(\times\) over the current state of the art.
Results
In this study, the authors compare the Server-Garbler protocol with their proposed optimizations (Client-Garbler, LPHE-enabled, and WSA-optimal). They conduct evaluations across various network-dataset pairs, setting client-side storage capacities to 16, 32, and 64 GB for the Server-Garbler protocol. For their proposed Client-Garbler protocol, they allocate the client-side storage capacity to the lowest setting (16 GB), sufficient for storing a single inference pre-compute. The server-side storage capacity is set to 10 TB, with a total available bandwidth of 1 Gbps. Arrival rates are varied to cover online-only and maximal sustainable throughput regions, simulating over 24 hours and averaging results over 50 independent runs.
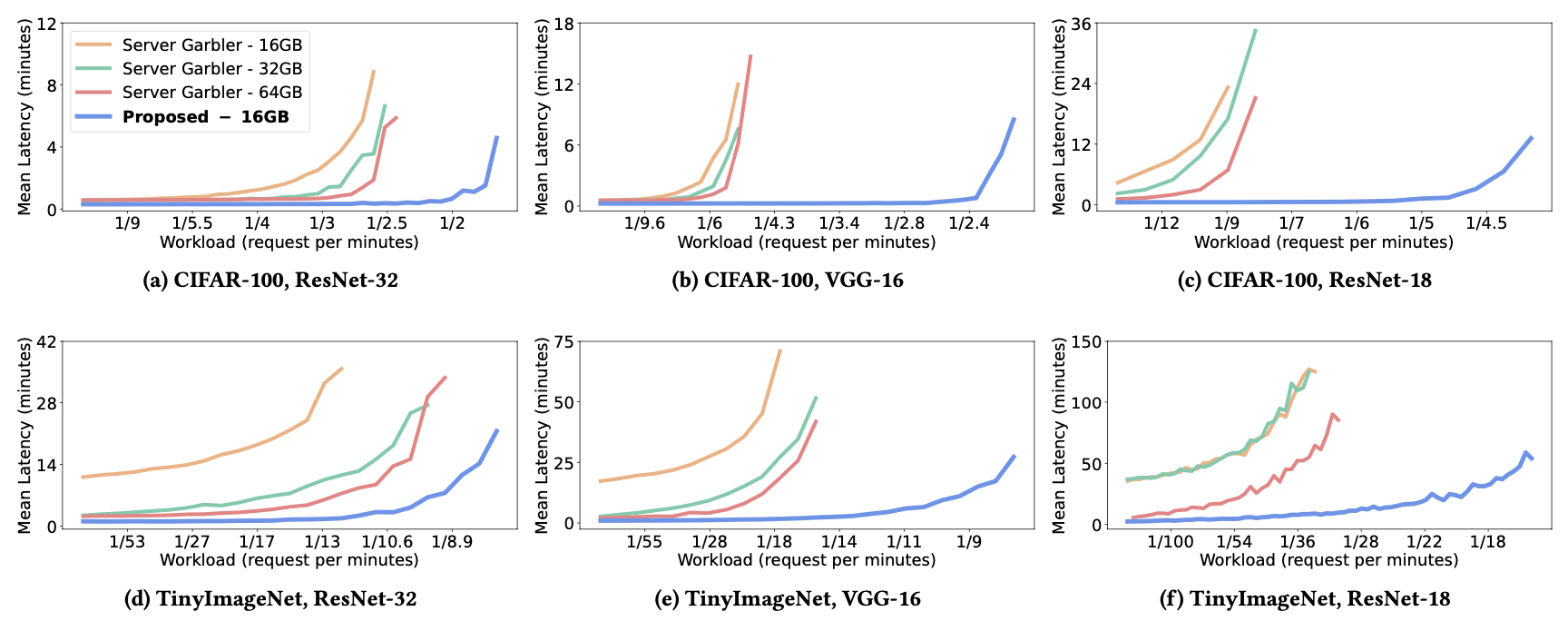
For CIFAR-100 (Figure 2), both Server-Garbler and Client-Garbler can store at least a single inference pre-compute across all storage capacities, enabling separate offline and online phases. However, Server-Garbler’s mean inference latency quickly rises to maximum sustainable throughput, even with increased client-side storage capacity. This is due to inference request arrival rates outpacing offline phase engagement, necessitating online cost incurred.
The authors’ optimizations result in lower mean inference latency compared to Server-Garbler, thanks to reduced client-storage pressure and computation/communication latency. Additionally, their protocol demonstrates lower latency than Server-Garbler at low arrival rates, as the server handles GC evaluation, allowing sufficient time between requests to replenish pre-computes. Furthermore, their protocol sustains higher arrival rates, extending towards heavier workloads compared to prior work. For ResNet-18 on CIFAR-100, their protocol handles a request rate of 1 every 5 minutes, while Server-Garbler is capped at 1 inference request every 12 minutes.
Moving from CIFAR-100 to TinyImageNet, not all client-side storage settings enable Server-Garbler to engage in pre-computation or offline phases. Hence, offline costs are shifted entirely online, even for low arrival rates. The authors’ proposed protocol, however, performs both phases with just 16 GB of client storage. Moreover, Client-Garbler sustains higher arrival rates due to reduced compute and communication latency from LPHE and optimal WSA.
Critical Review
Pros
- The authors propose three novel optimizations (Client-Garbler, LPHE-enabled, and WSA-optimal) to improve inference latency, addressing system limitations in computation, communication, and storage.
- The paper conducts a thorough evaluation of various aspects of private inference protocols, considering both online and offline phases, and analyzing compute, communication, and storage overheads.
Cons
- While the paper provides promising results in simulations, the effectiveness of the proposed optimizations in real-world deployments remains to be validated.
Takeaways
In this paper, the authors conduct a comprehensive evaluation of system-level characteristics for cutting-edge hybrid PI protocols. Unlike previous studies focusing solely on individual inferences, they examine the arrival rates of inference requests. Through their experiments, they uncover significant offline costs that have been overlooked, including client storage limitations, slow communication, and lengthy computations. Their analysis of inference request arrival rates reveals that these costs cannot remain offline due to storage constraints and insufficient time between requests. Leveraging their insights, the authors propose three new optimizations to address client storage limitations, expedite computations, and reduce communication latency, resulting in a 1.8\(\times\) reduction in total PI time. Additionally, they explore potential future optimizations across the PI pipeline and their potential to enhance the practicality of PI. The authors aim to encourage researchers to consider the holistic effects on the entire system when optimizing PI.
References
- K. Garimella, Z. Ghodsi, N. K. Jha, S. Garg, and B. Reagen, “Characterizing and optimizing end-to-end systems for private inference,” in Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS ’23. ACM, Mar. 2023. [Online]. Available: http://dx.doi.org/10.1145/3582016.3582065