
Vision Transformers Explained: How ‘An Image Is Worth 16x16 Words’ Transformed Computer Vision
There are papers that improve existing methods, and then there are papers that reset the way we approach a problem. The 2020 paper “An Image is Worth 16x16 Words” by Dosovitskiy et al. did the latter for computer vision. At a time when convolutional neural networks (CNNs) were the default workhorse of visual understanding, this paper asked a bold question:
What if we ditched convolutions entirely and just used Transformers for images?
It sounded radical—and perhaps even naive back then. But hindsight has a funny way of making revolutions seem inevitable. Today, Vision Transformers (ViTs) are the backbone of everything from medical imaging models to large multimodal systems like CLIP and DALL·E. This blog dives deep into the seminal work that started it all.
Paper Summarized
In “An Image is Worth 16x16 Words,” the authors propose Vision Transformer (ViT)—a pure Transformer architecture (no convolutions!) applied to sequences of image patches. Each image is split into non-overlapping patches (e.g., 16×16 pixels), which are flattened and treated like tokens in a sentence. These “visual words” are then processed by a standard Transformer encoder, just like text tokens in NLP.
No spatial convolutions. No hand-crafted inductive biases. Just global self-attention.
The surprising part? With sufficient data and compute, ViT matched or exceeded the performance of state-of-the-art CNNs on image classification benchmarks.
Why This Research Matters: Challenging the CNN Monoculture
Before ViT, convolutional networks ruled vision. And for good reason—they’re data-efficient, robust to spatial shifts, and inspired by biological vision systems. But they also come with built-in assumptions: locality, translation invariance, hierarchical processing.
Transformers, on the other hand, are data-hungry generalists that learn relationships from scratch. Their dominance in NLP stemmed from their ability to model long-range dependencies and scale with data. ViT tested whether those same principles could be applied to visual inputs.
This paper mattered because it:
- Unified NLP and vision architectures under the Transformer umbrella.
- Eliminated architectural handcrafting in favor of data-driven learning.
- Opened the door for multimodal models where language and vision share the same backbone.
ViT wasn’t just a new model. It was a declaration: maybe we don’t need vision-specific models at all.
Methodology: How Vision Transformers Work
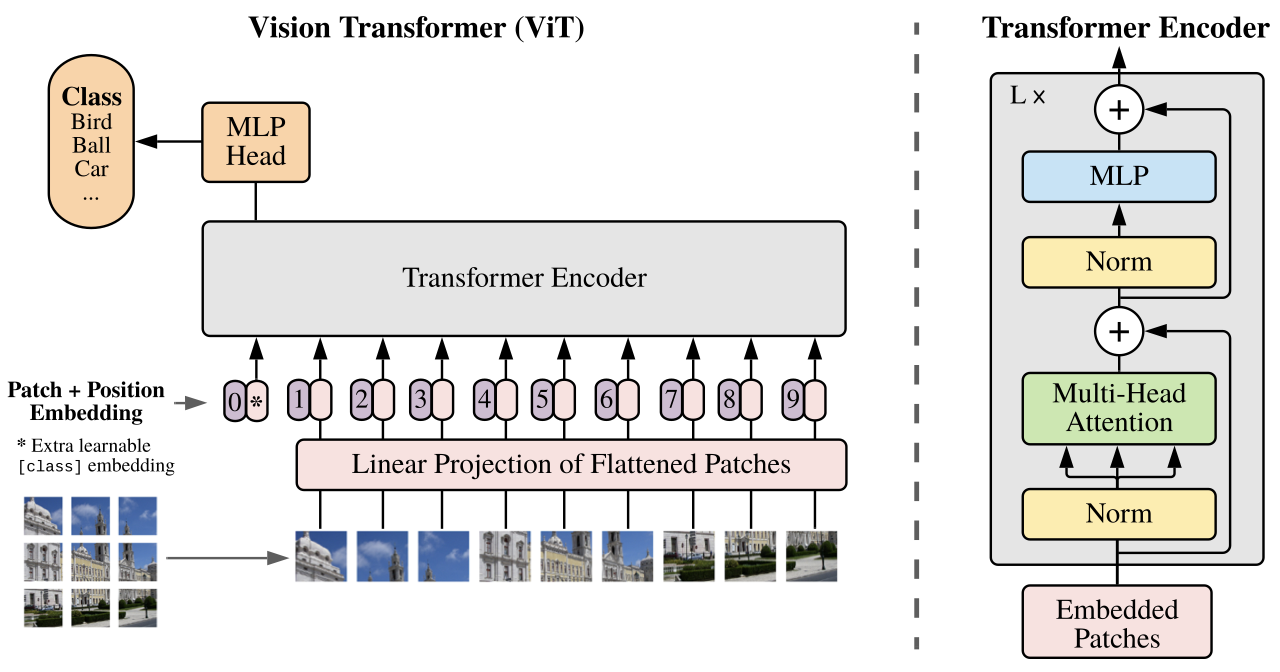
The core idea of ViT is disarmingly simple. Here’s how it works:
Patchify the Image
An image of size \(H \times W \times C\) is divided into a grid of non-overlapping patches, each of size \(P \times P\). For a 224×224 image with 16×16 patches, you get \((224 / 16)^2 = 196\) patches. Each patch is flattened into a 1D vector (length \(P^2 \times C\)).
Linear Projection + Positional Encoding
Each patch vector is linearly projected to a fixed embedding size (say, 768 dimensions). Positional embeddings are added to retain spatial ordering—just like in NLP.
They also prepend a learnable [CLS] token, which aggregates information across patches and is used for final classification.
Transformer Encoder
This sequence of patch embeddings (plus the CLS token) is fed into a vanilla Transformer encoder—multi-head self-attention layers with layer norm, feedforward blocks, residuals, and all the usual suspects.
Classification
After processing, the output corresponding to the CLS token is fed into an MLP head for classification.
No convolutions. No recurrence. Just pure attention.
Experimental Setup and Findings
The authors trained ViTs on ImageNet, ImageNet-21k (14M images), and JFT-300M (a private Google dataset) to test the effect of data scale.
Key Observations:
- ViT struggles on small datasets like ImageNet-1k when trained from scratch. It underperforms ResNets and other CNNs unless pre-trained on much larger datasets.
- With enough data, ViT surpasses CNNs. When pre-trained on ImageNet-21k or JFT and fine-tuned on ImageNet, ViT matched or exceeded ResNet performance.
- Scale matters. Larger models (ViT-B, ViT-L, ViT-H) consistently benefited from more data and compute. This mirrored trends in NLP (e.g., BERT → GPT-3).
- Training is faster. Thanks to global receptive fields and no recurrence, ViT converges faster than comparably-sized CNNs during pretraining.
- Simpler pipeline. No custom heads, spatial pyramids, or handcrafted inductive biases were needed. ViT learned everything from scratch.
Impact and Applications
The impact of this paper is hard to overstate. It kicked off a Transformer renaissance in vision, leading to:
- Vision-language models: CLIP, ALIGN, Flamingo, and others use ViT backbones for image encoders.
- Multimodal learning: Transformers made it easier to plug images into text-dominant models like GPT.
- Unified architectures: ViTs serve as the foundation for image captioning, segmentation (e.g., Mask2Former), and diffusion models.
- Open-source models: ViT models (via libraries like timm, HuggingFace, and PyTorch Image Models) are now widely available and widely adopted.
- Hardware optimization: ViT’s regular structure aligns well with TPUs and GPU accelerators, improving throughput in large-scale pipelines.
In short, ViT helped vision graduate into the Transformer era.
Reflections, Critique, and What’s Next
Limitations
- Data hunger: ViT needs lots of data to shine. On small datasets, CNNs remain more effective without pretraining.
- No inductive bias: While this can be a strength, it also means ViT doesn’t exploit spatial priors that are useful in low-data regimes.
- Interpretability: Self-attention maps offer some insights, but it’s still hard to reason about what ViT “sees” compared to CNNs with saliency maps.
- Patch-level artifacts: Non-overlapping patches can sometimes miss fine details (later addressed by hybrids like Swin Transformer).
What Followed:
- Data-efficient ViTs: DeiT (by Facebook) showed ViT can be trained on ImageNet-1k using distillation.
- Hierarchical ViTs: Swin Transformer introduced a CNN-like inductive hierarchy for better local-global fusion.
- Hybrid models: ConvNeXt, ConvFormer, and others revisit convolutions in light of ViT’s findings.
- Multiscale attention: Papers like CoaT, Twins, and CrossViT attempt to combine the best of both worlds.
Final Thoughts
“An Image is Worth 16x16 Words” wasn’t just a clever title—it was a pivot point for the entire field. What struck me most wasn’t just that Transformers can do vision, but that they don’t need special treatment to do it well. That elegance—treating image patches like words, letting attention do the rest—is what made this paper timeless.
The paper also raises a broader question that we’re still wrestling with:
Should we design models to encode human priors, or should we let them discover everything from data?
ViT leans heavily toward the latter. And with the rise of foundation models, it seems the field is leaning that way too.
If you’re a researcher or engineer working in vision—or just someone who cares about ML architecture—this paper is worth more than 16x16 words. It’s worth a spot in your mental toolbox.
Explore My ViT Implementations
If you’re interested in seeing how ViT works under the hood—or want to try it out yourself—check out my open-source projects:
- Vision Transformers: A clean implementation of ViT from this paper, trained on Fashion MNIST. Achieves 88.62% accuracy in just 10 epochs.
- Efficient ViT: Optimizes ViT training performance using custom CUDA kernels for FlashAttention, resulting in an 18.56% speedup for a 85.9M parameter ViT model.
Dive in, fork it, and feel free to reach out with questions or ideas.
References
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, & Neil Houlsby. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. [Online]. Available: https://doi.org/10.48550/arXiv.2010.11929