
Meta’s Segment Anything Model: Breakthrough in Image Segmentation
Image segmentation has always felt like one of those problems in computer vision that’s deceptively simple. You look at a photo and think, “Hey, just draw lines around the object.” But getting a machine to see the same way we do—to segment a cat from a couch, or a shadow from a sidewalk—is anything but trivial. The “Segment Anything” paper from Meta AI, spearheaded by Alexander Kirillov and team, doesn’t just propose a new model—it redefines how we should be thinking about segmentation entirely.
This post dives into what makes Segment Anything a landmark contribution: from the audacious ambition of building a foundation model for segmentation, to the practical magic of interactive masks. Let’s unpack this research.
What is Segment Anything?
At its core, Segment Anything (SA) introduces a general-purpose, promptable segmentation model—called SAM—that can segment any object in an image, given a user-defined “prompt” (like a point, a bounding box, or a rough mask). Unlike traditional segmentation models that are rigidly trained on specific categories, SAM is designed to generalize to unseen objects and concepts.
Think of SAM like the GPT of segmentation: it doesn’t need to be re-trained to tackle a new task—it just needs a hint. The model responds to prompts to output pixel-accurate masks with astonishing speed and flexibility.

Why This Research Matters
The motivation here is both visionary and practical. Image segmentation has always been siloed: semantic segmentation, instance segmentation, panoptic segmentation—each with its own datasets, networks, and quirks. And worse, most of these systems are closed-vocabulary—they know how to segment only what they’ve been trained to recognize.
SAM shifts the paradigm. It proposes a single model that can segment anything—even objects it has never seen—without category labels. This kind of generality is essential as we move toward more adaptive, foundation-style models in vision, similar to what LLMs did for NLP.
Why is this important?
- For annotation: SAM can generate masks automatically with little human input, slashing the cost of creating labeled datasets.
- For generalization: It removes the bottleneck of closed-category segmentation—so it can segment a space alien or a novel surgical tool just as easily as a car or a cat.
- For interactivity: Users can guide the segmentation using simple prompts, making it an intuitive interface for downstream tasks.
Methodology
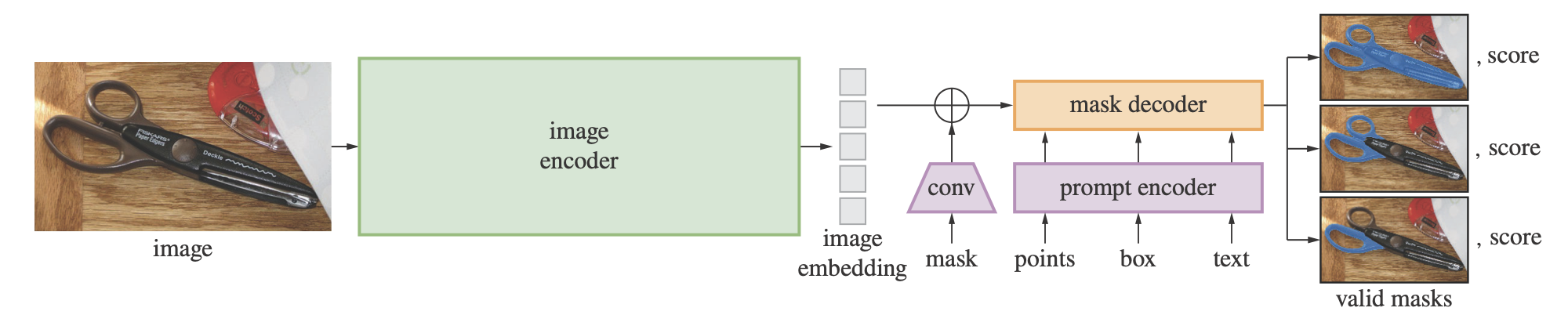
SAM’s architecture is elegant and highly modular, comprising three key components:
Image Encoder (a ViT-G backbone)
This is a heavy-duty vision transformer (over 1B params) that encodes the input image once, producing dense image embeddings. This step is slow but done only once per image—everything else is fast.
Prompt Encoder
Prompts—points, boxes, masks—are embedded into the same space as the image embeddings. Spatial inputs (like points or boxes) are encoded via positional embeddings, while masks are encoded with a convolutional network.
Mask Decoder
This lightweight decoder fuses image and prompt embeddings to predict high-resolution segmentation masks in real-time (~50ms per mask). It predicts multiple masks per prompt, each with a confidence score—essentially proposing multiple plausible segmentations.
The decoder doesn’t rely on category labels. Instead, it treats segmentation as a general matching problem between prompts and image regions.
Bonus: SAM is promptable. That is, it doesn’t just process an image—it interacts with it based on user guidance. This makes it more usable in practical settings, from labeling pipelines to interactive apps.
Experimental Setup and Results
Here’s where things get really interesting: SAM wasn’t evaluated like your typical segmentation model.
Dataset Creation – SA-1B
The authors created SA-1B, the largest segmentation dataset to date—over 1 billion masks across 11 million images. But here’s the twist: these masks weren’t manually labeled. They were generated by SAM itself, in a semi-automatic pipeline with human oversight.
This makes SAM one of the rare cases where a model bootstraps its own dataset. It’s reminiscent of how self-play improved AlphaGo or how LLMs train on scraped web data. Meta released both the model and dataset—an open-source move that’s as strategic as it is generous.
Evaluation
SAM was tested on a range of tasks:
- Zero-shot generalization to novel datasets (COCO, LVIS, FSS): It performed surprisingly well despite not being explicitly trained on them.
- Interactive segmentation benchmarks: Given user points or boxes, SAM consistently outperformed prior interactive segmentation tools in both accuracy and speed.
- Data efficiency: In fine-tuning downstream segmentation models, pretraining with SAM-generated masks led to better performance with less human annotation.
The takeaway? SAM isn’t the best-performing model in all tasks—but it’s often good enough, and dramatically more flexible.
Applications and Real-World Impact
SAM’s generality unlocks a broad range of use-cases:
- Dataset creation: SAM can help bootstrap labeled datasets across domains (e.g., agriculture, medical imaging) where expert annotations are expensive.
- Robotics and AR: Prompt-based segmentation means a robot or headset can adaptively interact with its surroundings using user cues.
- Creative tools: Graphic designers and video editors can use SAM as an intuitive cutout tool, segmenting arbitrary objects with just a click.
- Medical workflows: With proper fine-tuning, SAM could accelerate tumor annotation or surgical planning by segmenting novel tools or tissues.
It’s the kind of infrastructure-level model that makes other applications faster, cheaper, and more scalable.
Critique and Future Directions
While SAM is impressive, it’s not without caveats.
Limitations
- Not panoptic or semantic out of the box: SAM outputs masks, not labels. It doesn’t “know” what it’s segmenting—just where. To get full semantic segmentation, you’ll need an object detector or classifier on top.
- Heavy image encoder: The ViT-G backbone is massive. This makes real-time applications on edge devices a challenge without distillation or compression.
- Ambiguity in mask quality: The model can return multiple masks per prompt. While that’s great for recall, it may be less useful in workflows where precision or clarity is key.
- Prompt dependence: In zero-shot settings, SAM needs well-placed prompts to work well. It’s not “fully automatic” in that sense.
Future Work
- Integrating language understanding: Imagine prompting SAM with text (“segment the leftmost dog”)—a natural next step toward multimodal vision-language models.
- Lightweight or distilled variants for mobile and real-time use.
- Expanding into video segmentation, leveraging temporal consistency.
- More nuanced uncertainty modeling, especially in medical and safety-critical domains.
Final Thoughts
Segment Anything isn’t just a model—it’s a philosophy shift in how we think about computer vision. Instead of building narrow tools for narrow tasks, SAM shows us how a single model can serve as a segmentation foundation for an entire ecosystem of tasks.
In a way, SAM’s biggest contribution isn’t its raw accuracy, but its modularity, generality, and openness. It lowers the barrier to segmentation the same way Transformers lowered the barrier to language modeling.
For researchers like us, it’s an invitation: What else can we make promptable? What other bottlenecks in ML can be reframed as interactive, general-purpose systems?
If SAM is any clue, the future of vision isn’t models that “see” better—but ones that adapt better.
References
- Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, & Ross Girshick. (2023). Segment Anything. [Online]. Available: https://doi.org/10.48550/arXiv.2304.02643