
Flamingo Explained: Few-Shot Learning for Vision-Language Understanding
There’s something magical about few-shot learning. You give a model a couple of examples—say, a few image–caption pairs—and it suddenly starts “getting it.” In NLP, this magic moment arrived with large language models like GPT-3. But vision-language tasks? They’ve been lagging behind.
That’s where Flamingo comes in. In “Flamingo: a Visual Language Model for Few-Shot Learning” by Jean-Baptiste Alayrac and colleagues at DeepMind, the authors push vision-language models into the few-shot world. Flamingo can answer image-based questions, describe videos, or even do multimodal reasoning without fine-tuning—just by seeing a handful of examples in its context.
It’s a bold step toward multimodal foundation models that work the way humans do: by combining context with prior knowledge, rather than retraining for every new task.
Paper Summarized
Flamingo is a visual language model designed for few-shot learning across a wide variety of multimodal tasks. It builds on a pretrained language model (LM) and vision encoder, then bridges them with novel “perceiver resampler” layers that allow the LM to attend to visual information without retraining the LM from scratch.
Once built, Flamingo can be given just a few in-context examples—image–text or video–text pairs—and it can generalize to tasks it’s never explicitly trained for.
Why This Research Matters
Before Flamingo, most vision-language models (e.g., CLIP, ALIGN) were trained in a task-specific way—classification, captioning, VQA—each requiring large-scale supervised datasets. These models could transfer to related tasks, but not with the fluid adaptability we see in text-only LMs.
Flamingo matters because it removes that bottleneck:
- For researchers: It means we can prototype vision-language tasks without curating millions of labeled samples.
- For industry: It opens the door to interactive, multimodal assistants that learn on the fly from a few examples, much like ChatGPT does in text.
- For the field: It’s a step toward true multimodal foundation models that scale and adapt across domains.
In short, Flamingo shifts multimodal AI from a “train-for-every-task” paradigm to an “adapt-in-context” paradigm.
Methodology – The Flamingo Architecture
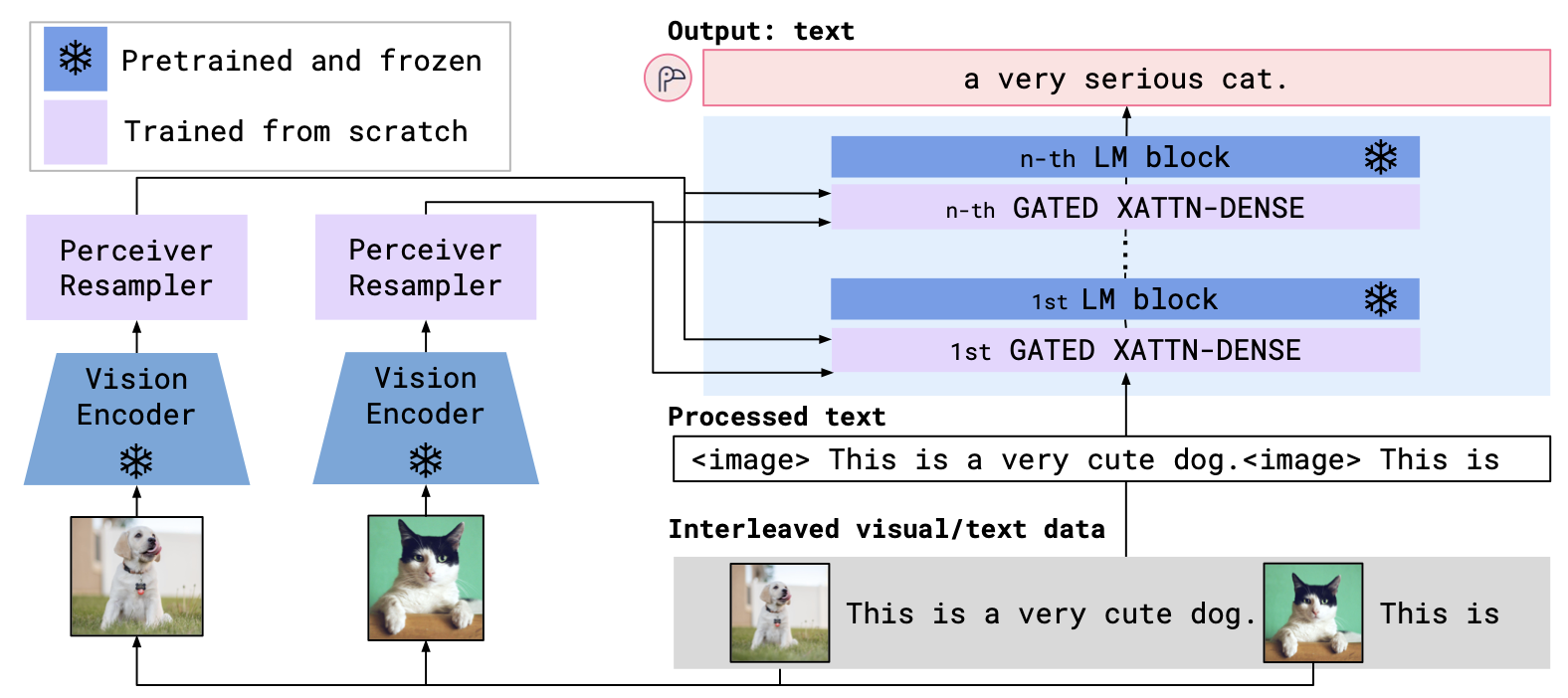
Flamingo’s design is a careful balance of reusing powerful pretrained models and adding lightweight multimodal integration.
Vision Encoder
A pretrained vision model (often a CLIP-style image encoder) processes each image or video frame into a set of embeddings.
Perceiver Resampler
This is one of Flamingo’s key innovations. Instead of dumping hundreds of vision embeddings directly into the language model (which would be inefficient and noisy), the perceiver resampler compresses them into a fixed number of latent tokens that still retain the relevant visual context. Think of it as distilling a whole photo album into a concise set of “visual notes” for the LM.
Language Model Backbone
A frozen, large-scale autoregressive LM (like Chinchilla or GPT-style models) handles the sequence modeling. Importantly, the LM weights are not fine-tuned—the integration happens via additional cross-attention layers.
Cross-Attention Gating
Flamingo interleaves visual tokens and text tokens in a way that allows the LM to attend to visual context only when needed. This keeps the LM’s language capabilities intact while enabling visual grounding.
Multimodal Training
The entire system is trained on a massive mix of image–text and video–text data, covering diverse sources. The goal is not to make it perfect at any one dataset, but to give it broad visual–linguistic grounding so it can adapt quickly in few-shot settings.
Experiments and Results
Flamingo was evaluated on a suite of benchmarks across multiple modalities:
- Image Captioning: MS COCO, NoCaps
- Visual Question Answering (VQA): VQAv2, OK-VQA, ScienceQA
- Video Understanding: MSRVTT, ActivityNet Captions
- Specialized Domains: Medical VQA datasets, chart/diagram understanding
Key Takeaways:
- Few-shot Strength: In 1–16 shot settings, Flamingo dramatically outperformed previous multimodal models, often approaching the performance of fully fine-tuned task-specific systems.
- Generalization: On datasets it was never explicitly trained on, Flamingo’s in-context learning abilities were still strong—mirroring the zero/few-shot behavior of GPT-3.
- Multimodal Reasoning: It showed capability in answering compositional queries (e.g., “How many blue objects are to the left of the red chair?”) without task-specific retraining.
Interestingly, scaling both the LM size and the visual pretraining data improved performance across the board—reinforcing the scaling laws we’ve seen in NLP.
Applications and Impact
Flamingo’s approach has implications across research and applied AI:
- Assistive Tools: Systems that can describe surroundings or answer visual questions for accessibility.
- Education: Interactive tutoring with diagrams, maps, and historical images.
- Video Analytics: Understanding events from surveillance or sports footage in a few-shot setup.
- Domain Adaptation: Medical imaging or satellite imagery tasks with minimal annotated data.
More broadly, Flamingo sets a template for how to merge strong unimodal models into flexible, multimodal generalists.
Critique and Future Directions
Limitations:
- Compute & Data Intensive: Pretraining Flamingo at DeepMind scale is far from accessible for most labs.
- Hallucination Risk: Like text-only LMs, Flamingo sometimes generates plausible but wrong answers—now with visual context.
- Bias Inheritance: It inherits biases from both the vision encoder and the LM, which may be compounded in certain tasks.
- No True Interleaving: While Flamingo can handle sequences of images and text, the interactions are still mediated by fixed attention patterns rather than fully dynamic multimodal reasoning.
Future Directions:
- Smaller, Efficient Flamingos: Distillation or LoRA-style adapters for resource-constrained settings.
- Better Visual Compression: Improving the perceiver resampler to capture fine details without ballooning token count.
- Interactive Multimodality: Moving toward conversational, turn-by-turn multimodal assistants.
- Integration with Agents: Pairing Flamingo-like models with tool use for grounded reasoning (e.g., querying external knowledge bases for factual verification).
Final Thoughts
Flamingo feels like a glimpse into the future of AI—one where models aren’t locked into single modalities or rigid training objectives, but instead can learn and adapt on the fly, just like humans. By fusing large-scale pretrained vision and language models with an elegant bridging mechanism, Flamingo delivers on the promise of few-shot multimodal learning.
The real genius here isn’t just in the architecture—it’s in the philosophy: don’t throw away the strengths of your pretrained giants; find a way to make them talk to each other.
For those of us working at the intersection of ML research and real-world deployment, Flamingo offers both inspiration and a blueprint. It’s a reminder that the next big leap might not be about inventing entirely new models, but about connecting the great ones we already have.
References
- Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, & Karen Simonyan. (2022). Flamingo: a Visual Language Model for Few-Shot Learning. [Online]. Available: https://doi.org/10.48550/arXiv.2204.14198